it started as a joke on postmodern theory, got accepted in academic articles. Later same happened with computer science and mathematical articles. -> shows how language functions in specific social settings,
look at algorithms, see how they work
computed generated erotic texts--can't tell (stereotypical tone, more easy to generate)
- study "grammar", looking at code
- everything predefine, nevertheless seems human made..(=realistic?)
algorithm learns to speak (shakespeare)-->feeding a lot of text, build math model, optimizing
www.youtube.com/watch?v=qv6UVOQ0F44 computer learning winning/playing video games
masked "types" like in commedia dell'arte
-------------
starting from tools, start playing
explore tools in different ways (don't need to know programming)
computer generated bullshit
text-mining/data-mining-->can use pattern library too
"the annotating has been done long time ago..by shakespeare"
responding to computer generated spam
- / an inventory of experiences
- "they looked at the website, they didn't read it" nuclear w. parody. exploiting ritualized language situations
- / an inventory of absences
- / a collective glossary
- ritualized language situation
- / an inventory of questions
- / an inventory of tensions
- automation, activism
**********************************************
21st August
round of presentation/ideas:
Gijs: Generate texts from / for politicians
Anna: From Barcelona, working with code for interactive installations. Interested in the track to be able to generate content which can pass a turing test. Also can feed it to other tracks? Can we generate text for politicians based on "langue de bois" text? Can this text be used in politics to get to an agreement? Therefore, can we replace politicians by politic bots?
Ricardo from Porto : interested in text-generation with a Dada-ist approach. Emulating interest ; create system to replicate, rather than passing Turing test like humans. Also worked with automated lay-outing these generated texts to turn them into objects.
Ana Isabel: also from Porto, designer. Collaborating with Ricardo. Has been experimenting with text. Have Portugese material, also other material they can share. Fado lyrics, texts from Parlement, also done experiments with newstitles.
Loraine: Observing
Wembo: Graphic designer, previous project was a Prejudice Generator (executing/speaking without thinking). Grammar structures for prejudice, local variations. (combination of different populations to make the generated text more and more absurd)
Prejudice different from place to place, learning to be as absurd and offensive as human beings
Jara: Language research group, contemporary poetry, in Madrid. Worried about depolitization of the new conceptualists, and interested in tech approach of their work. Euraca (?) group. Present languaging. Mediation through technological layers, as well as contextual or oral ones. Trying to learn simple methods of text manipulation [euraca: about https://seminarioeuraca.wordpress.com/about/ // conceptualismos yankis: https://seminarioeuraca.wordpress.com/programa3/ ]
Raphael: curious to see how for we can go. If code can become text, can code generate code again. Perhaps not only code, but also SVG. How graphical can these generated results be?
Clipart generator, after having the progran learn about it from OpenClipArt. A program that learns about shapes and can generate them
raw semantic, mark down
Hans: diverse background. Little bit of programming, little bit statistics.
Use the program as a political activist.
Catherine: get more familiar with the text generator as a writing and reading machine. Take it as a political tool based on a collection of texts. Same interest in the “langue de bois” discourses on Text & Data Mining
Illegaly accessing sources of copyrighted texts for data-mining (there are exceptions for education purposes)
Samuel, graphic designer. Worked on a chat bot, based on DB. Interested about how Neural Networks are done.
interest in markov chains, neural networks,
Andrea : studied graphic design but drifted away from it, interest in language - topical research -- interest on ritualistic aspect of language, experimental poetry, constructed as if was made by a machine. Interest in poetry made as if it would be made by machines, but actually made by humans. Interested in this shifts.
An: part of botopera-team that made dead authors re-enact as chatbots; interest in having 'contemporary' behaviours for Beatrix Botter: http://publicdomainday.constantvzw.org/#1943
***
Two methods/approaches to work with text:
- sintax and language-based, the most easy to get in
- neural networks (most challeging)
***
## Tools
Dada engine, a C program
http://dev.null.org/dadaengine/
Does’t need to get into the code
But you need to compile the package. Look at the README-file: after extracting you need to go into the dada-engine folder and to do 'configure', 'make' and then 'sudo make install' (The sudo is needed to have the permission to create a directory). Probably you get errors and have first to install the following files: bison and flex (with 'sudo apt-get install bison' and 'sudo apt-get install flex'.)
people working with Ubuntu need to install also makeinfo (sudo apt-get install texinfo)
Tests to generate some text (example): dada scripts/manifesto.pb
The NonIsmist Manifesto:
1. language is an illusion.
2. culture is a myth.
The ParaNihilist Manifesto:
1. there is no recovery.
2. reality is a myth.
The NonSurObjectivist Manifesto:
1. class is an illusion.
2. technology is a myth.
Examples:
> open the .pb file
Limitations: make sure that all the possibilities and rules are in there
Recurrent neural networks
http://googleresearch.blogspot.co.uk/2015/07/deepdream-code-example-for-visualizing.html
https://github.com/google/deepdream
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
https://github.com/karpathy/char-rnn
My first pseudo-Shakespeare produced through this RNN: [[Shaky blurb]]
Oops, the model of German political speeches (24,4 Mb of text) needs 463050 x 7s = 37 days to calculate
A first result with only 0,5% of the calculations[[German_blurb]]
Mirco RNN python version
https://gist.githubusercontent.com/karpathy/d4dee566867f8291f086/raw/17d79be172916066982f6ec8886ecf5ba1aa43bd/min-char-rnn.py
If you run it with python 3 like me, here is an adapted version :
https://gist.github.com/raphaelbastide/11ae4bb5e454e5c5239f
An: i'm reading this: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
but I have difficulties understanding some of the schemes - stgh for a break ;-)
A python Patent Generator : http://lav.io/2014/05/transform-any-text-into-a-patent-application/
Dasher, eye-tracking for typing
https://en.wikipedia.org/wiki/Dasher_%28software%29
http://www.inference.phy.cam.ac.uk/dasher/
(Ana & Ricardo are playing with this for probabilistic text generation. See the current progress at [[Dasherpoetry]] )
----- second round (post-lunch)
Ricardo/Ana: We feed dasher with a corpus of Fado, portuguese music lyrics -> [[Dasherpoetry]]
Working on alternative input for the interface to generate text.
Possible corpus to try: fado lyrics; portuguese parliament debates; recipes; code (tried it with kernel.c);
Ann: Installing dada engine
Hans: installed neural network library; now feeding it
Raphael: running minimal RNN python library to generate SVG
- -
22/08 - Cath & Wembo
Dada Mining Engine - txt generator from TDM grey literature (let's try)
http://www.sas.com/gms/redirect.jsp?detail=GMS16435_22380&gclid=CjwKEAjw9dWuBRDFs9mHv-C9_FkSJADo58iMfl_Sl5Pfgi_atBK8lC2scmwTo5Pie4g-e7fx21avhhoCyVvw_wcB
Data mining (the analysis step of the "Knowledge Discovery in Databases" process, or KDD),[1] an interdisciplinary subfield of computer science,[2][3][4] is the computational process of discovering patterns in large data sets ("big data") involving methods at the intersection of artificial intelligence, machine learning, statistics, and database systems.[2] The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use.
teenage (female) language generators:
http://www.smithsonianmag.com/smart-news/teenage-girls-have-been-revolutionizing-language-16th-century-180956216/?no-ist
planes of the euraca dialectizer (in Spanish, thou...):
https://seminarioeuraca.files.wordpress.com/2012/10/planos-del-dialectizador-para-la-construcciocc81n-de-zanjas.pdf
this interesting as an exampe of a (Visual) 3 dimensional space created from 4 letter words in english (begining with a certain letter)....
each point in space is a word and a surface 'wraps' the points (using 'marching cube algorithm - as is used in MRI scans...) to sho clustering of similar words with in the 3D space.
https://www.processing.org/exhibition/works/base26/index_link.html
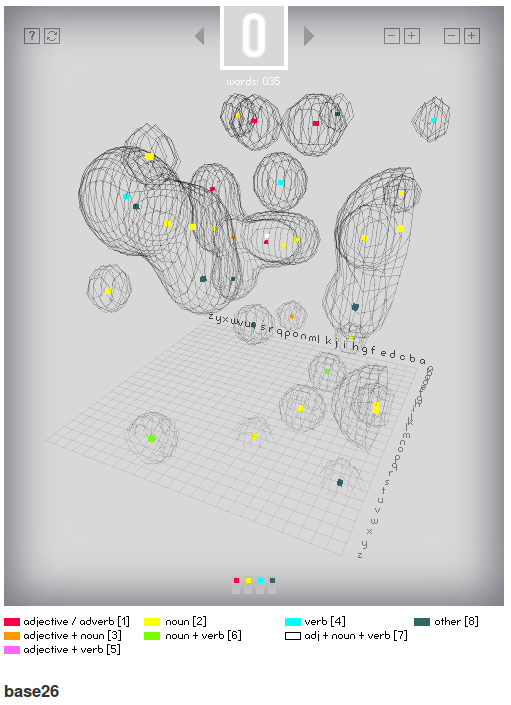
../images/base26.png
Obama speech generator:
See a message from the president on http://10.9.8.57
Get the data:
A json dump of the database is available at http://10.9.8.57/export
You can download it with the following command
wget 10.9.8.57/export -o export.json
Which will download the data into a file called 'export.json' in your current directory.
It's a list of object / dictionaries with the keys
url => the url of the page from which the speech/transscript was downloaded
text => the origninal text (only the parts spoken by Obama)
cleaned_text => a (roughly) cleaned version where double spaces and annotations like (applause) & (laughter) have been removed
Video grep
The Piet Zwart Institute's Wiki has a nice page on multiple ways of editing video:
https://pzwiki.wdka.nl/mediadesign/Editing_in/code
One of those ways is videogrep:
http://lav.io/2014/06/videogrep-automatic-supercuts-with-python/
http://zulko.github.io/blog/2014/06/21/some-more-videogreping-with-python/
Interview machine
More an idea than a finished product yet. Basic idea is to use the Dada Engine for its structured templates, but make it more open by creating such pb-files with scraped information.
At the moment the only thing it does is scraping headlines from Reuters and posing a question. This can be enlarged with an answer module based on the article itself. How exactly to create the answer raises a lot of possible options from simple pre-cooked structures to using more advanced methods using semantic ontologies.
../text-generation/interview%20machine.py