training common sense - day 3
adjectives
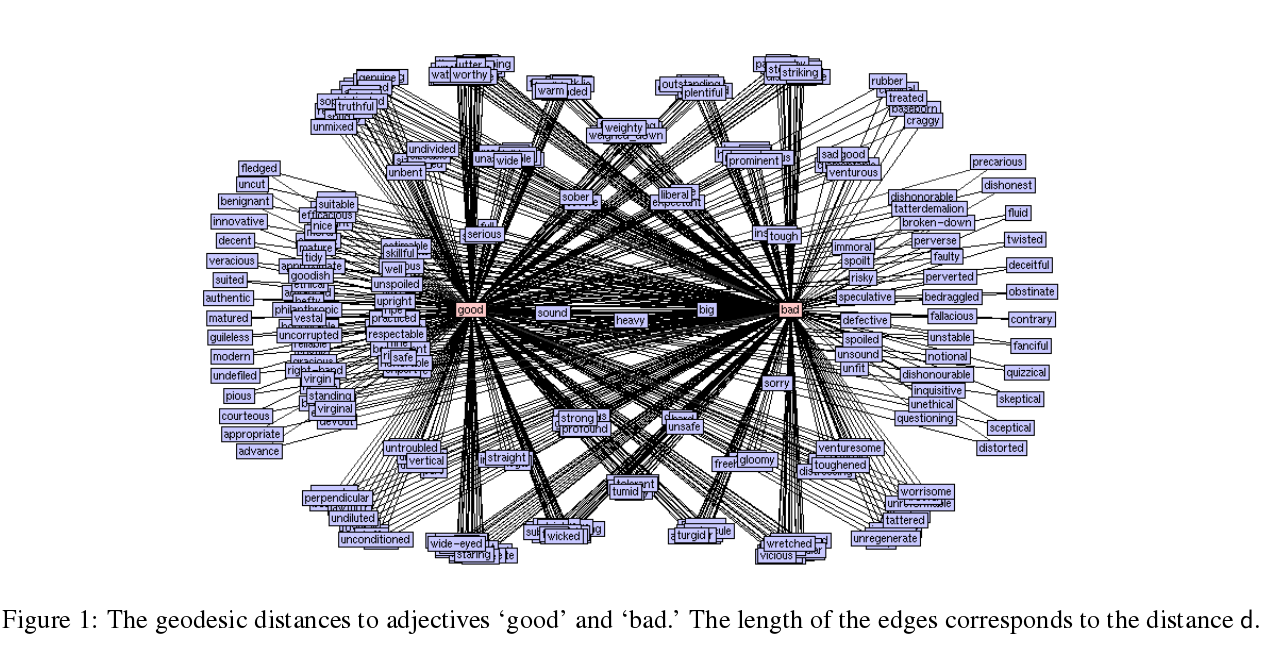
../training-common-sense/sources/pictures/good-bad.png
from: Using WordNet to Measure Semantic Orientations of Adjectives --> http://www.lrec-conf.org/proceedings/lrec2004/pdf/734.pdf
../training-common-sense/sources/pictures/sentiWordNet.png
http://sentiwordnet.isti.cnr.it/
adjectives in WordNet
references
Using WordNet to Measure Semantic Orientations of Adjectives --> http://www.lrec-conf.org/proceedings/lrec2004/pdf/734.pdf
book about WordNet --> ../training-common-sense/sources/texts/wordnet-an-electronic-lexical-database-language-speech-and-communication.9780262061971.33119.pdf
history of WordNet
George A. Miller is initiator of WordNet,
from two different fields, he worked on a computational lexicon:
- * AI
- - George A. Miller + Philip N. Johnson-Laird
- - componential lexicon
- --> looking for significant atoms
- - ±1976 - 1985
- * Cognitive Studies, Psychology
- - relational lexicon
- --> IS-A-KIND-OF relations
- - ±1985 and onwards
- WordNet developed at Princeton University, at Cognitive Studies
work @ WordNet on adjectives
- - Philip N. Johnson-Laird
- 266 pairs of antonymous adjectives ------------> 25 classes of nouns
- - Christiane Fellbaum
- 266 pairs of antonymous adjectives ------------> 25 classes of verbs
- - Kitty Miller
Philip N. Johnson-Laird
(born 12 October 1936) is a professor at Princeton University's Department of Psychology and author of several notable books on human cognition and the psychology of reasoning.
— from: https://en.wikipedia.org/wiki/Philip_Johnson-Laird
profile: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3250179/
portrait: 
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3250179/bin/pnas.1117174108unfig01.gif
When complex technology starts spiraling out of hand, this abundance of information hinders our ability to make reliable decisions.
“Eventually,” Johnson-Laird says, “the computational demands overwhelm them, and this often culminates in catastrophes.”
— from: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3250179/
worked on the grouping of adjectives to classes of nouns.
Can we find this file?
- --> searched for it, but cannot find it, also no references to it in articles.
adjectives in Pattern
references
"Vreselijk mooi!" (terribly beautiful): A Subjectivity Lexicon for Dutch Adjectives --> http://www.clips.ua.ac.be/sites/default/files/desmedt-subjectivity.pdf
- 1. Introduction
- - "Textual information can be broadly categorized into two types: objective facts and subjective opinions (Liu, 2010)." --> first sentence of the article
- - two approaches for Sentiment Analysis:
- - using subjectivity lexicons (Taboada et al., 2011)
- - using machine learning text classification (Pang et al., 2002)
commodification of difference
Looking at 'the cyclic commodification of difference', and entry points for a critique of text-mining (thank you Seda Guerses)
Alison Adam, Gay men, Gaydar and the commodification of difference (2008)
Alison Adam, A Feminist Critique of Artificial Intelligence http://ejw.sagepub.com/content/2/3/355.refs (1995)
to compute the semantic similarity/relateness/mathematical-relation between adjectives
departing from the article "Vreselijk mooi!" --> http://www.clips.ua.ac.be/sites/default/files/desmedt-subjectivity.pdf
- - 1.100 adjectives manually annotated on polarity and subjectivity
- - then, they want to extend that set to 5.000 adjectives
- 3.1. Using Distributional Extraction
- There is a wellknown approach in computational linguistics in which semantic relatedness between words is extracted from distributional information (see e.g. Van de Cruys 2010 for an example for Dutch). The method uses a vector space model with adjectives as vectors (i.e., matrix rows) and nouns as vector features (i.e., matrix columns). The value for each vector feature represents the frequency an adjective precedes a noun. It is then possible to take the cosine of the angle between two vectors as a measure of similarity (cosine similarity). In other words, adjectives followed by the same nouns are more semantically related than adjectives followed by different
adjectives nouns. The method then uses dimensionality reduction and clustering by cosine distance to create groups of semantically related words.
then, we looked at: Van de Cruys 2010, called Mining for Meaning, chapter 2 (page 31) --> https://www.rug.nl/research/portal/files/14692283/14complete.pdf
matrix of adjectives
a1 [ n1 n2 . . . . . . ny]
a2 [ n1 n2 . . . . . . ny]
a3 [ n1 n2 . . . . . . ny]
a4 [ n1 n2 . . . . . . ny]
a5 [ n1 n2 . . . . . . ny]
a6 [ n1 n2 . . . . . . ny]
ax [ n1 n2 . . . . . . ny]
example: micro/minimal context of adjectives
- - Looking at the relation between adjectives and nouns, is a way to have a sense of the context that a word appears in.
- - What nouns could adjectives modify?
- - you can calculate the relation between a certain adjective to a certain noun (a1-n1)
a1 n1 --> amazing book occur 5 times together
a2 n1 --> awesome book occur 10 times together
a3 n1 --> beautiful book occur 15 times together
a1 n1 --> amazing book
a2 n2 --> awesome person
a3 n3 --> beautiful flower
- --> these nouns fall under the same class of nouns
bright, brilliant, apocalyptic ... future
brilliant, well-written, interesting ... book
mathematical 'relation' or 'similarity' vs. semantic 'relation' or 'similarity'
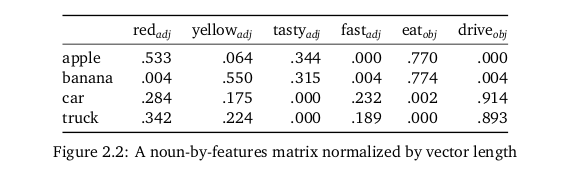
../training-common-sense/sources/pictures/similarity-of-adjectives-related-to-nouns_from_mining-for-meaning-2.png
red (often), yellow (sometimes), tasty (very often), fast (hardly ever) ... apple
red (hardly ever), yellow (very often), tasty (often), fast (hardly ever)... banana
red (sometimes), yellow (sometimes), tasty (hardly ever), fast (often) ... car
red (very often), yellow (sometimes), tasty (hadly ever), fast (sometimes) ... truck
Algorithm used = "co-sine similarity measure"
then... (the text continues)
We applied this approach to automatically annotate new adjectives, based on their semantic relatedness to gold1000 [= hand annotated] adjectives. From the TWNC [Twente Nieuws Corpus (TwNC)] (Ordelman et al., 2002), we analyzed 3,000,000 words and selected the top 2,500 most frequent nouns. For each adjective in TWNC that is also in the CORNETTO [dutch language, dutch counterpart WordNet] database, we counted the number of times it directly precedes one or more of these top nouns, resulting in 5,784 adjective vectors with 2,500 vector features. For each gold1000 [= hand-annotated] adjective we then used cosine similarity [= algorithm described by Tim van de Cruys] to retrieve the top 20 most similar nearest neighbors [what is neighbouring what?]. For fantastisch (fantastic) the top five nearest neighbors are: geweldig (great, 70%), prachtig (beautiful, 51%), uitstekend (excellent, 50%), prima (fine, 50%), mooi (nice, 49%) and goed (good, 47%).
beautiful - book: x times
beautiful - person: z times
beautiful - apple: y times
---
adjective vector
features: book, person, apple (ny)
translated into a mathematical matrix, it will look like:
horrible - book: y times
example try:
- For each gold1000 --> fantastic
- appears in the gold1000 with 10 different nouns --> a1[n1, n2, n3, n4, n5, n6, n7, n8, n9, n10] --> is the adjective vector
- great, beautiful, excellent, fine, nice, good
- --> are already hand-annotated / or not
- --> have adjective vectors as well
- --> are these two adjective vectors then compared?
en-sentiment.xml
pattern's sentiment analysis uses a list of English adjectives in a xml file (in the pattern-2.6.zip file, it's located in pattern-2.6/pattern/text/en/). this file is also used by other projects (mentionning pattern) found after a very quick research :
TextBlob (Simple, Pythonic, text processing--Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more) https://github.com/sloria/TextBlob (this software uses two other sentiment analyzers)
Emotional (Subjectivtiy and sentiment/polarity analysis library for Node.js) https://github.com/ticup/emotional
fr-sentiment.xml
pattern's sentiment analysis for French uses a list of French adjectives in a xml file (in the pattern-2.6.zip file, it's located in pattern-2.6/pattern/text/fr/). this file is also used by other projects (mentionning pattern) found after a very quick research :
TextBlob (Simple, Pythonic, text processing--Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more) https://github.com/sloria/TextBlob (it seems that it is not the same version than for pattern, version 1.0 instead of 1.1 fpr pattern 2.6)
how about going forwards?
text-mining methods, text-mining culture
- document the steps that has been put on the table during this edition of Relearn, and has been produced since Cqrrelations
- how would you make it (a text-mining-process) better?
- - what is better?
- - less suggestive?
- - more efficient?
- - ...
- - does it become better by
- - giving critique on it?
- - play with it? being goofy?
- what would an algorithm do?
- let's make a critical fork of Pattern (how are we going to call it ? Pattern the critical edition, PatternPlus, FlattenPlus...)
- - as a form of annotation of Pattern
- - there is already annotation present from the Pattern team, but this is focused on an urge to show how the data speaks
- - additional files that go into the package, reacting on the files of Pattern
- - which might include a check-me.txt file
- - in some packages there is an ADD-TO-DO or ADD-FIX-ME file
Google Group question: sentiment_score()
answered by Tom de Smedt

../training-common-sense/sources/pictures/if-happy-is-0.0-something-is-wrong.png
https://groups.google.com/forum/#!topic/pattern-for-python/FTeqb0p5eFM (this question)
Pattern on the web
Pattern's Github --> https://github.com/clips/pattern
Pattern's Google Group --> https://groups.google.com/forum/#!forum/pattern-for-python
backing-up: Cqrrelations
Cqrrelations is a work session lasting from 12 till 23 January 2015, in which a wide range of forms of life coming from different backgrounds in arts, literature, science and computing will gather to reflect on the influence of models and digital traces over our daily reality and language. The work session is a space for theories and practices, for experiments, discussions, prototypes… Human and non-human (in-)expertise will facilitate the exploration the topic. Parts of the process will be documented on this platform, possibly to end up in some forms of publication later on.
Organised by Constant with the support of deBurenPublic events are organised in collaboration with deBuren, CPDP and Recyclart
www.cqrrelations.constantvzw.org/
pictures of the week: http://gallery3.constantvzw.org/index.php/Cqrrelations