pattern.search
The pattern.search module has a pattern matching system similar to regular expressions, that can be used to search a string by syntax (word function) or by semantics (word meaning).
It can be used by itself or with other pattern modules: web | db | en | search | vector | graph.

Documentation
Searching + matching in a nutshell
The search() function takes a string (e.g., a word or a sequence of words) and returns a list of non-overlapping matches in the given sentence. The match() function returns the first match, or None. Both functions call compile(), which takes a string and returns a Pattern object.
search(pattern, sentence)
match(pattern, sentence)
compile(pattern)
>>> from pattern.search import search
>>> print search('rabbit', 'big white rabbit')
[Match(words=[Word('rabbit')])]Search strings can contain a wildcard character at the *start, at the end*, at *both* ends or in*between:
>>> print search('rabbit*', 'big white rabbit')
>>> print search('rabbit*', 'big white rabbits')
[Match(words=[Word('rabbit')])]
[Match(words=[Word('rabbits')])]
Search strings can contain multiple options separated by a vertical dash:
>>> print search('rabbit|cony|bunny', 'big black bunny')
[Match(words=[Word('bunny')])]Syntactical pattern matching
The examples above can also be resolved with (faster) regular expressions. The pattern.search module is more useful with parsed sentences. The pattern.en module has a parser that takes a string and assigns a part-of-speech tag to each word (e.g., NN = noun, VB = verb, JJ = adjective). The parser also groups words into chunks (e.g., JJ + NN = NP = noun phrase) and finds word lemmata (was → be).
A parsed Sentence or Text can be searched by part-of-speech tags:
>>> from pattern.search import search
>>> from pattern.en import parsetree
>>>
>>> t = parsetree('big white rabbit')
>>> print t
>>> print
>>> print search('JJ', t) # all adjectives
>>> print search('NN', t) # all nouns
>>> print search('NP', t) # all noun phrases
[Sentence('big/JJ/B-NP/O white/JJ/I-NP/O rabbit/NN/I-NP/O')]
[Match(words=[Word(u'big/JJ')]), Match(words=[Word(u'white/JJ')])]
[Match(words=[Word(u'rabbit/NN')])]
[Match(words=[Word(u'big/JJ'), Word(u'white/JJ'), Word(u'rabbit/NN')])]Semantical pattern matching
A Taxonomy can be used to define semantical categories of words. Say we want to extract flower names from a text. The search pattern is rather clumsy: "rose|lily|daisy|daffodil|begonia". A more robust approach is to work with a taxonomy:
>>> from pattern.search import search, taxonomy
>>> from pattern.en import parsetree
>>>
>>> for f in ('rose', 'lily', 'daisy', 'daffodil', 'begonia'):
>>> taxonomy.append(f, type='flower')
>>>
>>> t = parsetree('A field of white daffodils.', lemmata=True)
>>> print t
>>> print
>>> print search('FLOWER', t)
[Sentence('A/DT/B-NP/O/a field/NN/I-NP/O/field of/IN/B-PP/B-PNP/of'
'white/JJ/B-NP/I-PNP/white daffodils/NNS/I-NP/I-PNP/daffodil ././O/O/.')]
[Match(words=[Word(u'white/JJ'), Word(u'daffodils/NNS')])]
Note how the search pattern has "FLOWER" in uppercase. Since search() is case-insensitive, uppercase words are recognized as taxonomy terms (i.e., FLOWER = rose + lily + daisy + daffodil + begonia). Furthermore, since lemmata were parsed, daffodils is recognized as the plural form of daffodil (the lemma), and as such also part of FLOWER.
Note that the returned match is white daffodils. Since search() is (by default) greedy, the whole NP chunk is matched. In other words, white daffodils is regarded as a more specific instance of daffodil.
Pattern
A Pattern is a sequence of constraints that matches certain phrases in a (parsed) sentence. Each constraint can match a word in the sentence. If a number of successive words corresponds to the entire sequence of constraints, the phrase is a match. The search is case-insensitive.
Constraints can be constructed for syntax (e.g., find all adjectives) and semantics (e.g., find all product names). For example, Pattern.fromstring("NP be * than NP") matches phrases such as the cat was faster than the mouse, and Chuck Norris is cooler than Dolph Lundgren, since NP matches any noun phrase. With TAXONOMY, the global taxonomy is used to categorize words.
pattern = Pattern(sequence=[])
pattern = Pattern.fromstring(string, taxonomy=TAXONOMY)
pattern.sequence # List of Constraint objects. pattern.groups # List of groups, each a list of Constraint objects. pattern.strict # Disable greedy matching?
pattern.scan(string) pattern.search(sentence) pattern.match(sentence, start=0)
- Pattern.scan() returns True if Sentence(string) may yield matches.
It can be faster to scan a tagged string, before casting it to a Sentence or Text and searching it. - Pattern.search() returns a list of Match objects from the given sentence.
- Pattern.match() returns the first Match found in the given sentence, or None.
>>> from pattern.search import Pattern
>>> from pattern.en import parsetree
>>>
>>> t = parsetree('Chuck Norris is cooler than Dolph Lundgren.', lemmata=True)
>>> p = Pattern.fromstring('{NP} be * than {NP}')
>>> m = p.match(t)
>>> print m.group(1)
>>> print m.group(2)
[Word(u'Chuck/NNP'), Word(u'Norris/NNP')]
[Word(u'Dolph/NNP'), Word(u'Lundgren/NNP')]
Constraint
A Constraint matches a set of (tagged) words and taxonomy terms. For example:
- Constraint.fromstring('with|of') matches either with or of.
- Constraint.fromstring('JJ?') matches any adjective tagged JJ, but it is optional.
- Constraint.fromstring('NP|SBJ') matches subject noun phrases.
- Constraint.fromstring('QUANTITY') matches siblings of QUANTITY in the taxonomy.
constraint = Constraint(
words = [],
tags = [],
chunks = [],
roles = [],
taxa = [],
optional = False,
multiple = False,
first = False,
taxonomy = TAXONOMY,
exclude = None,
custom = None )constraint = Constraint.fromstring(string, **kwargs)
constraint.index constraint.string constraint.words # List of allowed words/lemmata (of, with, ...) constraint.tags # List of allowed parts-of-speech (NN, JJ, ...) constraint.chunks # List of allowed chunk types (NP, VP, ...) constraint.roles # List of allowed chunk roles (SBJ, OBJ, ...) constraint.taxa # List of allowed taxonomy terms. constraint.taxonomy # Taxonomy used for lookup. constraint.optional # True => matches zero or one word. constraint.multiple # True => matches one or more words. constraint.first # True => can only match first word. constraint.exclude # None, or Constraint of disallowed options. constraint.custom # function(word) returns True if match.
constraint.match(word)
Constraint string syntax
Constraint.fromstring() returns a new Constraint from the given string. It takes the same optional parameters as the constructor. Uppercase words in the given string indicate a part-of-speech tag (e.g., NN, JJ, VP) or a taxonomy term (e.g. PRODUCT, PERSON).
Some characters like | or ? are special. They affect how the constraint is interpreted:
| Character | Example | Description |
| ( | (JJ) | Wrapper for an optional constraint (deprecated). |
| [ | [Mac OS X | Windows Vista] | Wrapper for a constraint that has spaces. |
| { | DT {JJ?} NN | Wrapper for match groups, e.g., Match.group(1). |
| _ | Windows_Vista | Converted to a space. |
| | | ADJP|ADVP | Separator for different options. |
| * | JJ* | Used as a wildcard character. |
| ! | !be|VB* | Used in front of words/tags that are not allowed. |
| ? | JJ? | Used as a suffix, constraint is optional. |
| + | RB|JJ+ or JJ?+ or *+ | Used as a suffix, constraint can span multiple words. |
| ^ | ^hello | Used as a prefix, constraint can only match first word. |
The characters listed in the table must be escaped if used as content (e.g., "\?"). You can use the module's escape() function. For example, escape("hello?") returns "hello\?".
Constraint matching
Constraint.match() returns True if the given string or Word is part of the constraint:
- the word (or its lemma) occurs in Constraint.words, OR,
- the word (or its lemma) occurs in Constraint.taxa taxonomy tree, AND
- the word tags and/or chunk tags match those defined in the constraint.
It is case-insensitive. Individual terms in Constraint.words can contain wildcards (*). Some part-of-speech-tags can also contain wildcards: NN*, VB*, JJ*, RB*, PR*, WP*.
The following example demonstrates the use of optional and multiple constraints:
>>> from pattern.search import search
>>> from pattern.en import parsetree
>>>
>>> t = parsetree('tasty cat food')
>>> print t
>>> print
>>> print search('DT? RB? JJ? NN+', t)
[Sentence('tasty/JJ/B-NP/O cat/NN/I-NP/O food/NN/I-NP/O')]
[Match(words=[Word(u'tasty/JJ'), Word(u'cat/NN')]), Word(u'food/NN')])]The pattern matches successive nouns (NN), optionally preceded by a determiner (DT), adverb (RB) and/or adjective (JJ). It matches anything from food to cat food, tasty cat food, the tasty cat food, etc.
Constraint = greedy
The pattern.en parser groups words that belong together into chunks. For example, the black cat is one chunk, tagged NP (i.e., a noun phrase). The head of the chunk is cat. By default, when a constraint matches the chunk head, it will greedily match the entire chunk. This means that if we search for cat and the sentence has a big black cat, the entire chunk will be returned.
This behavior can be disabled by passing a STRICT flag to Pattern, compile(), search() or match():
>>> from pattern.search import search, STRICT
>>> from pattern.en import parsetree
>>>
>>> t = parsetree('The black cat is lurking in the tree.')
>>> print search('cat', t)
[Match(words=[Word(u'The/DT'), Word(u'black/JJ'), Word(u'cat/NN')])]
>>> print search('cat', t, STRICT)
[Match(words=[Word(u'cat/NN')])]
Match
Pattern.search() returns a list of Match objects, where each match is a list of successive Word objects.
match = Match(pattern, words=[])
match.pattern # Pattern source. match.words # List of Word objects. match.string # String of words separated with a space. match.start # Index of first word in sentence. match.stop # Index of last word in sentence + 1.
match.group(index, chunked=False) match.constraint(word) match.constraints(chunk) match.constituents(constraint=None)
- Match.group() returns a list of Word objects matching the constraints in a { } group.
- Match.constraint() returns the Constraint that matched the given Word, or None.
- Match.constraints() returns the list of constraints that matched the given Chunk.
- Match.constituents() returns a list of Word and Chunk objects, with successive words grouped into chunks whenever possible. Optionally, returns only chunks/words that matched the given Constraint (or list of constraints). Chunks are only available if a Sentence or Text was given (i.e., not for plain strings).
>>> from pattern.search import match
>>> from pattern.en import parsetree
>>>
>>> t = parsetree('The turtle was faster than the hare.', lemmata=True)
>>> m = match('NP be ADJP|ADVP than NP', t)
>>>
>>> for w in m.words:
>>> print w, '\t =>', m.constraint(w)
Word(u'The/DT') => Constraint(chunks=['NP'])
Word(u'turtle/NN') => Constraint(chunks=['NP'])
Word(u'was/VBD') => Constraint(words=['be'])
Word(u'faster/RBR') => Constraint(chunks=['ADJP', 'ADVP'])
Word(u'than/IN') => Constraint(words=['than'])
Word(u'the/DT') => Constraint(chunks=['NP'])
Word(u'hare/NN') => Constraint(chunks=['NP'])
Match groups
Match groups in the search pattern can be used to quickly retrieve what you need from a Match:
>>> t = parsetree('the big black dog')
>>> m = match('DT {JJ?+ NN}', t)
>>> print m.group(0) # full pattern
>>> print m.group(1) # {JJ?+ NN}
>>> print m.group(1).string
[Word(u'the/DT'), Word(u'big/JJ'), Word(u'black/JJ'), Word(u'dog/NN')]
[Word(u'big/JJ'), Word(u'black/JJ'), Word(u'dog/NN')]
'big black dog'Match words
Each Word in a Match or Match.group() has the following attributes:
word = Word(sentence, string, tag=None, index=0)
word.string word.tag # Part-of-speech tag (e.g. NN, JJ). word.sentence # Sentence (a list of successive Words). word.index # Sentence index.
When search() or match() is given a string, Word objects are created when the Match is returned. When given a parsed Sentence, Word objects are linked from the sentence. These have extra attributes. For an overview of Sentence, Chunk and Word, see the parse tree documentation.
Taxonomy
A taxonomy is a hierarchical tree of words classified by semantic type. For example: a begonia is a flower, and a flower is a plant. Taxonomy terms can be used as constraints. For example, "FLOWER" will match flower as well as begonia, or any other flower that has been defined in the taxonomy. By default, constraints will retrieve terms from the global taxonomy.
taxonomy = Taxonomy()
taxonomy.case_sensitive # False by default. taxonomy.classifiers # List of Classifier objects.
taxonomy.append(term, type=None) taxonomy.remove(term)
taxonomy.classify(term) taxonomy.parents(term, recursive=False) taxonomy.children(term, recursive=False)
- Taxonomy.classify() returns the (most recent) semantic type for a given term.
If the term is not in the taxonomy, it will try Taxonomy.classifiers (see further). - Taxonomy.parents() returns a list of all semantic types for the given term.
- Taxonomy.children() returns a list of all terms for the given semantic type.
With recursive=True, traverses the entire branch.
For example:
>>> from pattern.search import taxonomy, search
>>>
>>> taxonomy.append('chicken', type='food')
>>> taxonomy.append('chicken', type='bird')
>>> taxonomy.append('penguin', type='bird')
>>> taxonomy.append('bird', type='animal')
>>>
>>> print taxonomy.parents('chicken')
>>> print taxonomy.children('animal', recursive=True)
>>> print
>>> print search('FOOD', "I'm eating chicken.")
['bird', 'food']
['bird', 'penguin', 'chicken']
[Match(words=[Word('chicken')])]Taxonomy classifier
A Classifier offers a rule-based approach to enrich the taxonomy. If a term is not in the taxonomy, it will iterate its list of classifiers. Each classifier is a set of functions that can be customized to yield the semantic type of a term.
classifier = Classifier(
parents = lambda term: [],
children = lambda term: [])classifier.parents(term) # Returns a list of parents for a term. classifier.children(term) # Returns a list of children for a term.
This is useful because taxonomy terms can't include wildcards (i.e., the * character is taken literally).
>>> from pattern.search import taxonomy, search
>>> from pattern.search import Classifier
>>>
>>> def parents(term):
>>> return ['quality'] if term.endswith('ness') else []
>>>
>>> taxonomy.classifiers.append(Classifier(parents))
>>> taxonomy.append('cat', type='animal')
>>>
>>> print search('QUALITY of a|an|the ANIMAL', 'the litheness of a cat')
[Match(words=[Word('litheness'), Word('of'), Word('a'), Word('cat')])]This example creates a classifier that tags words ending in -ness as quality (e.g., sharpness, greediness). This is more concise than manually adding all words ending in -ness to the taxonomy. The quality term is then used as a constraint. Remember to always define Classifier.parents(). For performance, Classifier.children() is not called in Constraint.match().
Taxonomy classifier from WordNet
The following example creates a rule-based taxonomy from the pattern.en.wordnet module:
>>> from pattern.search import taxonomy, WordNetClassifier
>>>
>>> taxonomy.classifiers.append(WordNetClassifier())
>>>
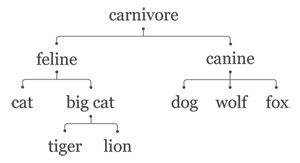
>>> print taxonomy.parents('cat', pos='NN')
>>> print taxonomy.parents('cat', pos='VB')
['feline']
['flog']|
|
Utility functions
The pattern.search module has a number of useful list functions:
unique(iterable) # Returns a new list with unique items.
find(function, iterable) # Returns first item for which function(item) is True.
product(iterable, repeat=1) # Returns a generator of all combinations of length n.
variations(iterable, optional=lambda item: False)
odict(items=[])
- product() returns a generator of all permutations, with replacement.
For example: product([1,2,3), repeat=2) yields:
[1,1], [1,2], [1,3], [2,1], [2,2], [2,3], [3,1], [3,2], [3,3] - variations() returns all variations of a sequence with optional items (in-order).
- odict() is a dictionary with ordered keys (e.g., like a stack).
The most recent keys will be returned first when traversing the dictionary.
odict.push() takes a (key, value)-tuple and sets the given key to the given value. If the key exists, it pushes the updated item to the top of the stack.