pattern
Pattern is a web mining module for the Python programming language.
It has tools for data mining (Google, Twitter and Wikipedia API, a web crawler, a HTML DOM parser), natural language processing (part-of-speech taggers, n-gram search, sentiment analysis, WordNet), machine learning (vector space model, clustering, SVM), network analysis and <canvas> visualization.
The module is free, well-document and bundled with 50+ examples and 350+ unit tests.

Download
 |
Pattern 2.6 | download (.zip, 23MB)
Reference: De Smedt, T. & Daelemans, W. (2012). SHA256 checksum of the .zip: |
Modules
Helper modules Command-line |
Contribute |
Installation
Pattern is written for Python 2.5+ (no support for Python 3 yet). The module has no external dependencies, except LSA in the pattern.vector module, which requires NumPy (installed by default on Mac OS X).
To install Pattern so that the module is available in all Python scripts, from the command line do:
> cd pattern-2.6 > python setup.py install
If you have pip, you can automatically download and install from the PyPi repository:
> pip install pattern
If none of the above works, you can make Python aware of the module in three ways:
- Put the pattern subfolder in the .zip archive in the same folder as your script.
- Put the pattern subfolder in the standard location for modules so it is available to all scripts:
c:\python27\Lib\site-packages\ (Windows),
/Library/Python/2.7/site-packages/ (Mac),
/usr/lib/python2.7/site-packages/ (Unix). - Add the location of the module to sys.path in your Python script, before importing it:
>>> import sys; sys.path.append('/users/tom/desktop/pattern')
>>> from pattern.web import Twitter
Quick overview
pattern.web
The pattern.web module is a web toolkit that contains API's (Google, Gmail, Bing, Twitter, Facebook, Wikipedia, Wiktionary, DBPedia, Flickr, ...), a robust HTML DOM parser and a web crawler.
>>> from pattern.web import Twitter, plaintext
>>>
>>> twitter = Twitter(language='en')
>>> for tweet in twitter.search('"more important than"', cached=False):
>>> print plaintext(tweet.text)
'The mobile web is more important than mobile apps.'
'Start slowly, direction is more important than speed.'
'Imagination is more important than knowledge. - Albert Einstein'
... pattern.en
The pattern.en module is a natural language processing (NLP) toolkit for English. Because language is ambiguous (e.g., I can ↔ a can) it uses statistical approaches + regular expressions. This means that it is fast, quite accurate and occasionally incorrect. It has a part-of-speech tagger that identifies word types (e.g., noun, verb, adjective), word inflection (conjugation, singularization) and a WordNet API.
>>> from pattern.en import parse >>> >>> s = 'The mobile web is more important than mobile apps.' >>> s = parse(s, relations=True, lemmata=True) >>> print s 'The/DT/B-NP/O/NP-SBJ-1/the mobile/JJ/I-NP/O/NP-SBJ-1/mobile' ...
| word | tag | chunk | role | id | pnp | lemma |
| The | DT | NP | SBJ | 1 | - | the |
| mobile | JJ | NP^ | SBJ | 1 | - | mobile |
| web | NN | NP^ | SBJ | 1 | - | web |
| is | VBZ | VP | - | 1 | - | be |
| more | RBR | ADJP | - | - | - | more |
| important | JJ | ADJP^ | - | - | - | important |
| than | IN | PP | - | - | PNP | than |
| mobile | JJ | NP | - | - | PNP | mobile |
| apps | NNS | NP^ | - | - | PNP | app |
| . | . | - | - | - | - | . |
The text has been annotated with word types, for example nouns (NN), verbs(VB), adjectives (JJ) and determiners (DT), word types (e.g., sentence subject SBJ) and prepositional noun phrases (PNP). To iterate over the parts in the tagged text we can construct a parse tree.
>>> from pattern.en import parsetree >>> >>> s = 'The mobile web is more important than mobile apps.' >>> s = parsetree(s) >>> for sentence in s: >>> for chunk in sentence.chunks: >>> for word in chunk.words: >>> print word, >>> print Word(u'The/DT') Word(u'mobile/JJ') Word(u'web/NN') Word(u'is/VBZ') Word(u'more/RBR') Word(u'important/JJ') Word(u'than/IN') Word(u'mobile/JJ') Word(u'apps/NNS')
Parsers for Spanish, French, Italian, German and Dutch are also available:
pattern.es | pattern.fr | pattern.it | pattern.de | pattern.nl
pattern.search
The pattern.search module contains a search algorithm to retrieve sequences of words (called n-grams) from tagged text.
>>> from pattern.en import parsetree
>>> from pattern.search import search
>>>
>>> s = 'The mobile web is more important than mobile apps.'
>>> s = parsetree(s, relations=True, lemmata=True)
>>>
>>> for match in search('NP be RB?+ important than NP', s):
>>> print match.constituents()[-1], '=>', \
>>> match.constituents()[0]
Chunk('mobile apps/NP') => Chunk('The mobile web/NP-SBJ-1')
The search pattern NP be RB?+ important than NP means any noun phrase (NP) followed by the verb to be, followed by zero or more adverbs (RB, e.g., much, more), followed by the words important than, followed by any noun phrase. It will also match "The mobile web will be much less important than mobile apps" and other grammatical variations.
pattern.vector
The pattern.vector module is a toolkit for machine learning, based on a vector space model of bag-of-words documents with weighted features (e.g., tf-idf) and distance metrics (e.g., cosine similarity, infogain). Models can be used for clustering (k-means, hierarchical), classification (Naive Bayes, Perceptron, k-NN, SVM) and latent semantic analysis (LSA).
>>> from pattern.web import Twitter
>>> from pattern.en import tag
>>> from pattern.vector import KNN, count
>>>
>>> twitter, knn = Twitter(), KNN()
>>>
>>> for i in range(1, 10):
>>> for tweet in twitter.search('#win OR #fail', start=i, count=100):
>>> s = tweet.text.lower()
>>> p = '#win' in s and 'WIN' or 'FAIL'
>>> v = tag(s)
>>> v = [word for word, pos in v if pos == 'JJ'] # JJ = adjective
>>> v = count(v)
>>> if v:
>>> knn.train(v, type=p)
>>>
>>> print knn.classify('sweet potato burger')
>>> print knn.classify('stupid autocorrect')
'WIN'
'FAIL' This example trains a classifier on adjectives mined from Twitter. First, tweets with hashtag #win or #fail are mined. For example: "$20 tip off a sweet little old lady today #win". The word part-of-speech tags are parsed, keeping only adjectives. Each tweet is transformed to a vector, a dictionary of adjective → count items, labeled WIN or FAIL. The classifier uses the vectors to learn which other, unknown tweets look more like WIN (e.g., sweet potato burger) or more like FAIL (e.g., stupid autocorrect).
pattern.graph
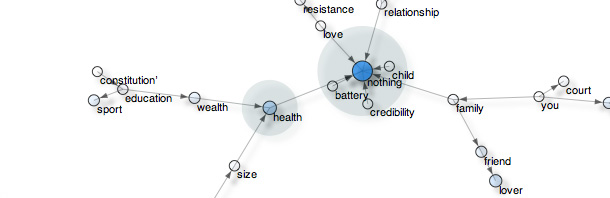
The pattern.graph module provides a graph data structure that represents relations between nodes (e.g., terms, concepts). Graphs can be exported as HTML <canvas> animations (demo). In the example below, more central nodes (= more incoming traffic) are colored in blue.
>>> from pattern.web import Bing, plaintext
>>> from pattern.en import parsetree
>>> from pattern.search import search
>>> from pattern.graph import Graph
>>>
>>> g = Graph()
>>> for i in range(10):
>>> for result in Bing().search('"more important than"', start=i+1, count=50):
>>> s = r.text.lower()
>>> s = plaintext(s)
>>> s = parsetree(s)
>>> p = '{NP} (VP) more important than {NP}'
>>> for m in search(p, s):
>>> x = m.group(1).string # NP left
>>> y = m.group(2).string # NP right
>>> if x not in g:
>>> g.add_node(x)
>>> if y not in g:
>>> g.add_node(y)
>>> g.add_edge(g[x], g[y], stroke=(0,0,0,0.75)) # R,G,B,A
>>>
>>> g = g.split()[0] # Largest subgraph.
>>>
>>> for n in g.sorted()[:40]: # Sort by Node.weight.
>>> n.fill = (0, 0.5, 1, 0.75 * n.weight)
>>>
>>> g.export('test', directed=True, weighted=0.6) Some relations (= edges) could use some extra post-processing, e.g., in nothing is more important than life, nothing is not more important than life.
Case studies
Case studies with hands-on source code examples.
|
|
modeling creativity with a semantic network of common sense (2013) This case study offers a computational model of creativity, by representing the mind as a semantic network of common sense, using pattern.graph & web. read more » |
|
|
|
using wiktionary to build an italian part-of-speech tagger (2013) This case study demonstrates how a part-of-speech tagger for Italian (see pattern.it) can be built by mining Wiktionary and Wikipedia. read more » |
|
|
|
using wikicorpus and nltk to build a spanish part-of-speech tagger (2012) This case study demonstrates how a part-of-speech tagger for Spanish (see pattern.es) can be built by using NLTK and the freely available Wikicorpus. read more » |
|
|
|
belgian elections, twitter sentiment analysis (2010) This case study uses sentiment analysis (e.g., positive or negative tone) on 7,500 Dutch and French tweets (see pattern.web | nl | fr) in the weeks before the Belgian 2010 elections. read more » |
|
|
|
web mining and visualization (2010) This case study uses a number of different approaches to mine, correlate and visualize about 6,000 Google News items and 70,000 tweets. read more » |