*A FEMINIST NET/WORK(ING) HOW-TO (RELEARN 2015)
=================================================
* Setup local server(s) & make your own network infrastructure, rather than "fixing the problems of internet access" by paying for increased bandwidth / data;
* Prefer "read/write" and negotiable networks to those that "just work";
* Prefer pocket servers to those in the clouds;
* Embrace a diversity of network topologies and different scales (machine to machine, local nodes, institutional infrastructure) and consider the implications of working with each; \
(Rather than a Web 2.0 model where resources must be uploaded onto "a 24/7 Internet" in order to share them; where sharing presupposes acceptance of non-negotiable / non-rewritable Terms of Service defined by market-leading global corporations)
* Invite participants to look critically at the implications of *any* infrastructural decisions, rather than imagining utopic and/or "killer" solutions;
* Aim to make that which is normally hidden and invisible (in contexts that tend to surveillance), explicit and shared (as a gesture of collective authorship), for instance:
* Instead of caching web resources (silently), imagine services to archive resources and share them locally as cookbooks or a digital library;
* Rather than logging servers and database accessible only by administrators, imagine (local) logs available for reading / editing by participants and published conditionally.
The Relearn Network-------------------------
The relearn network is a ["network with an attitude"](http://activearchives.org/wiki/Wiki_attitude). Many things that usually "just work" _do not_, and this inconvenience is intentional because the goal of the network is to inform its users about the conditions of its use and to encourage an active participation in (re)forming it. The network has some unique features:
* It's autonomous and is not setup to route traffic to the public Internet (there are still ways of reaching the outside, so stay tuned!).
* It is not setup to distribute addresses automatically (there is no *DHCP*).
* It is the simplest possible kind of network -- one that in fact you create by simply connecting computers together (either via ethernet cables or to the same wireless router) and deciding upon some network addresses; for this reason it's an infrastructure that's important to understand and be able to make tactical use of.
Connecting----------------
1. Join Wireless network "RELEARN5"
Because there is no automatic configuration setup, you will need to access the settings of the network to manually configure the connection.
Ffind the option of manually configure the network. I
2. Pick a card and configure to use static IP address
On the table are a stack of cards with IP addresses on them, please take one. Configure your wireless settings to connect to the Network with ssid "relearn" and with the IP address & netmask shown on the card.
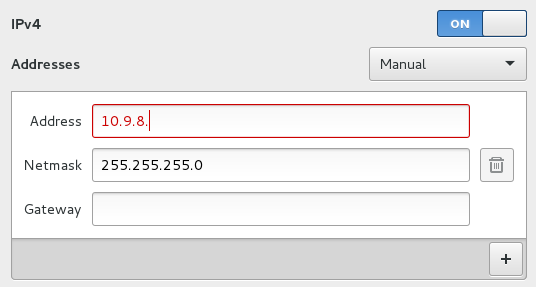
The SSID of the network is "relearn"; be sure to select Manual (and not automatic or DHCP). The IP address is the number on the card starting with "10.9.8.xxx". The Netmask is 255.255.255.0. Leave the gateway blank (or if it seems that you must enter something, then 0.0.0.0).
> setting your IP-address manually through the terminal
sudo ifconfig wlan0 10.9.8.xx netmask 255.255.255.0 up
ping 10.9.8.7 --> to check if the connection is established
How can you tell if it's working--------------------------------
Try typing the following address in your browser:
../
Congratulations! You are a member of the local relearn network and able to reach the server. You are not connected public Internet.
Context------------
According to [Source: http://faqintosh.com/risorse/en/guides/net/tcp/basic/](http://faqintosh.com/risorse/en/guides/net/tcp/basic/):
> An IP address in the most common format (named "IPv4") is a four bytes expression dot-divided.
> In an IP address the 4 bytes are represented by their value, there are 4 numbers from 0 to 255 in a format like: «192.168.183.15»
> An IP address must be unique in a network, and the Internet is a network.
> The IP address can be read from left to right, defining the address like in Country, Town, Street, Street Number. \
*However, it's not that simple.* In a simple network, every laptop, tablet or smart phone would have a unique address that would make it addressable (and thus accessible) to all other particpants of the network equally. *The Internet* does not in practice work that way, but in fact is (and always has been) a loose agglomeration of different networks, at different scales, with different aims and concerns. When you connect to a hotspot or plug in an ethernet cable to a laptop, you are assigned an address by *that particular* network (typically via a protocol called *DHCP* or Dynamic Host Configuration Protocol). This *IP address* is typically a special *reserved* number that belongs to *private networks* -- and thus is only really valid on the local network. (See [private networks](#Private_Networks)).
Depending on that network's design and infrastructure requests for content on the public Internet will be routed so that they "just work". Increasingly, however, certains things are designed to "not work" as network infrastructures are designed to limit certain activities: for instance: you typically cannot run a webserver on your laptop to host files to someone outside of your local network (as you don't have a public IP address); you might not be able to collect or send email from your email program (as activity on *ports* other than those used by the web (80 and 443) are blocked); protocols such as torrents may be banned outright; attempts to share your connection may cause your connection to be blocked; intermediary firewalls may block access to files based on their format and content and this blocking may or may not be indicated explicitly.
 showing net blocking in action in the UK (left) and Qatar (right); The latter make the fact of blocking explicit while the former misleadingly gives the appearance that the resource is missing or that the server has failed](img/NetworkBlockPagesMcIntyre.png)
Private Networks----------------------
>10.0.0.0 - 10.255.255.255 (10/8 prefix)\
>172.16.0.0 - 172.31.255.255 (172.16/12 prefix)\
>192.168.0.0 - 192.168.255.255 (192.168/16 prefix)\
>Source: [https://tools.ietf.org/html/rfc1918](https://tools.ietf.org/html/rfc1918)\
>See also: [https://en.wikipedia.org/wiki/Reserved_IP_addresses](https://en.wikipedia.org/wiki/Reserved_IP_addresses)
>
>Another special address is *127.0.0.1* aka *localhost* which always refers to the machine itself.
Netmask------------
An IP address is like a person's name and has two parts -- a shared part (like a family name) that identifies the network (subnet) you are a part of, and the second part (like a given name) is the unique identity within that subnet family. The netmask simply specifies where to make the split (how much of the address is shared and unique). To simplify it, 255 means that part of the address is part of the subnet, and 0 indicates the unique part. The most common netmask is 255.255.255.0 meaning that the first three numbers of the IP address give the subnet and the last number is the unique individual in that subnet.
| | | | | | |
|--------------|---:|---:|---:|---:|-|
|IP address |192.|168.| 1.| 23 | |
|+ Netmask |255.|255.|255.| 0 |Since this mask specifies the first 3 bytes,\
it can also be expressed compactly as 24 (bits)\
and the whole address could be written 192.168.1.23/24|
|= |--- |--- |--- |--- | |
|Subnet |192|168 |1 | |This is the *shared* part of the address;\
Any address starting with 192.168.1.xxx is "local" \
(part of the subnet) and can be reached directly \
(without an intermediate *gateway*).|
|Unique | | | | 23 |This number is a *unique* identity \
within the subnet.|
Links------
* [There is no internet](http://opentranscripts.org/transcript/there-is-no-internet/) and [What's wrong with the internet](http://loriemerson.net/2015/07/23/whats-wrong-with-the-internet-and-how-we-can-fix-it-interview-with-internet-pioneer-john-day/), Lori Emerson
* [The Network is Hostile](http://blog.cryptographyengineering.com/2015/08/the-network-is-hostile.html), Matthew Green
INSTALL YOURSELVES INTO RELEARN
*You are in an associative place called Zinneke. It hosts the 2015 edition of Relearn Summerschool (the third edition, after two which took place at Variable, also in the neighbourhood of Schaerbeek).
To get into this building you must enter this code: 1341 (take good note of it!)
*Sign up for tasks----> [[taking_care]]
*notetaking is not sharing is not documenting is not archiving is not publishing... or is it?
**Look at what happens when you use pads... : [[relearn thinking through/timeslider]]
(the timeslider is crooked: to use the timeslider drag the blue sliding cursor from the end and drag it back to the beginning!)
**Pick one element/question from that ongoing conversation and discuss it in the group. take care of taking notes, take notes with care.
(To make a new pad or link to an existing one, just put it in between double square brackets: [[Etherpad]] )
Today and during the whole week it's important to keep taking notes along the worksessions and discussions.
(And, by the way, relearn's website is also a modified version of etherpad, called ethertoff, made by OSP...)-> {relearn.be}
ANYONE CAN TYPE!!
let's do it
Oh and put your name in on the top right corner if you want to be identified!
yes!
no!
you can write here
you can also name others who haven't put a name on themselves, go define someone else's identity! Set up your name before someone does it for you!
me who is me ? juliane
the username is a lie
Hello :)
**Look at what happens when you use pads... : [[relearn thinking through/timeslider]]
(the timeslider is crooked: to use the timeslider drag the blue sliding cursor from the end and drag it back to the beginning!)
**Look at what happens when you use pads... : [[relearn thinking through/timeslider]]
(the timeslider is crooked: to use the timeslider drag the blue sliding cursor from the end and drag it back to the beginning!)
**Look at what happens when you use pads... : [[relearn thinking through/timeslider]]
(the timeslider is crooked: to use the timeslider drag the blue sliding cursor from the end and drag it back to the beginning!)
**Look at what happens when you use pads... : [[relearn thinking through/timeslider]]
(the timeslider is crooked: to use the timeslider drag the blue sliding cursor from the end and drag it back to the beginning!)
**Look at what happens when you use pads... : [[relearn thinking through/timeslider]]
(the timeslider is crooked: to use the timeslider drag the blue sliding cursor from the end and drag it back to the beginning!)
**Look at what happens when you use pads... : [[relearn thinking through/timeslider]]
(the timeslider is crooked: to use the timeslider drag the blue sliding cursor from the end and drag it back to the beginning!)
thinkin through: [[relearn thinking through]]
This table is both about Linux and if you would like to try it installing it or to run it from a live stick use the manual below.
About your operating system / Choose your linux
To start off a conversation about your operating system we've prepared some questions. Feel free to divert / extend / change / annotate. Feel free to do so on this pad!
Which operating system do you use and why?
Xubuntu---compability--otherwise would use mageia
Ubuntu->didn t know any better at the time of stepping to linux(it sort of works) it has also a nice design like a linux without too much complication?
ubuntu : it's easy to use but there are issues with it (though i'm not really intending to change at the moment, out of habit i guess).
I am on Manjaro which is a french / danish OS if I recall well, it is based on Arch linux. The community is friendly and small.
I am using Debian because it's easy to install and it gives you more options than Ubuntu (I like Gnome 3)
I am using Mint (Linux), after some experimenting with other systems (Debian, archlinux, crunchbang) it's the convenient option - why? Hmm. I stopped using Ubuntu at some point, because of the way they re-thought the repository as a shop, for example and started to pre-manage users into categories. So Mint is equally convenient, but does not come with that assumption. Also, I like the less hysterical approach to updating.
Ubuntu : first easy version to install
xubuntu-->lighter
Debian: it was the first I got and it stuck, I got fed up with OSX making choices for me (updates etc) and wanted more explicit control
Ubuntu: I use Linux since 2000 and Ubuntu was the first easy distribution without too much bugs. I still have Windows installed for last check of Word layout for work purposes
Ubuntu : I am still in a try out process / otherwise I also use Macosx
Ubunut - because i had to buy a new machine and it was the most compatable (i used elementary os previously)
Ubuntu & macosx. I'm poly.
I am (anna) using Ubuntu 14 becquse it's open and usefull for coders and developers.
I'm using windows because some of the software I'm using work only on this os
I'm using Ubuntu because it is easy to use and allows the openness I like of Linux
Ubuntu
ubuntu since april
Windows because I need it to run some softwares - which ones?mostly graphic design/image and video editing and video games
ok, but why linux??????????????????????
virtual machine a bit buggy
in windows copy-paste is horrible---phenomenology of copy-pasting
laptop died monday morning, new computer, new install--->new hardware-->new ubuntu(wanted to test on a live usb in shop before buying a machine-->looked bad upon, like a terrorist)
Debian. I started with Ubuntu, then moved to Fedora and now I use Debian. To start I needed an easier linux distro but as Ubuntu started to get evil I moved to a freeer distro
Debian, lots of debian (previously Win, Gentoo, Ubuntu, OSX)
OSX x2 victims :(
Linux Mint 14 Nadia (which means i am 3 versions behind... due to evident laziness)
OSX because I'm lazy to switch, but I could in theory, using less and less adobe stuff. Plus OSX is confortable lazy?
I slip in behind in my shame with osx
OS green pantone
debian because it's stable and free open source
Do you choose a distribuition for its community or philosophy?
yes philosophy, ideology and political
Discussion group 1
- annoying to be dependent on adobe, triyng to get over it
- Proposition: constitute 'communities of DETOX" - from google, adobe
- The main problem about switching to free software is the issues of ergonomy?
- Teaching photoshop and gimp in the same time (the specular)
- The problem with the 'insall party' philosophy is that it is presented as easy- Its not!
- the problem of the instinctiveness of corporate software (paradox of the 'super designed')
- 2003 in England: if you were dislectic you were given a MAC OS fro free (cos more intuitive for dislectic people)
- we can also do a DETOX for people having outdated linux versions!
yes, for this one and the previous one (Debian)
no
yezzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
for its community, becquse I always need help
Yes, Debian sort of ensures your system is "clean"
yes & yes
yes
actually not sure i ever chose. more just thought it was the only way for non-tech people
Do you feel ownership over your operating system?
I used to, more then I do now. It's become so habitual that I am not sure I notice, or I am aware, or think about it at the moment
not sure if i'd say ownership, but i feel connected to it (and I feel like I can make changes and ask questions)
not all the days, but i feel better when i see the macs new OS
no
not really. how so?
Increasingly, I've configured it very specifically to my tastes and needs. As I learn more about it I feel more confident to reinstall everything and make more explicit choices of what my system should be.
No
No No
No no no, why not?
First no answer is because I use it but I don,t contribute to it
little script to keep preferences every new install-->porting set up to new machines as well
ownership machine vs ownership system
20 reinstalls..plus editing..graphic as well..
More or less. Although UEFI is making life difficult for dual-boot installing.
Used to, but I feel like Ubuntu is not the same (wtf, app store?)... Keep meaning to switch to debian/mint or something lighter.
Not at all
Mostly yes, keeping the system free/libre gives an abstract & comfortable sense of control, I like the "personal" aspect of personal computing, making it "mine" is important
A bit, and responsability on the fact some things works and others I still need to figure out
not ownership. But certain dispossession in the good sense.
more or less,
Is it important to know how it works, untill which level?
Yes, though I cannot afford to think about it on a daily basis, I realise now you are asking. Also I forget and need to Relearn all the time.
yes but my knowledge of it is limited, though expanding, and i forget too. discovering layers is actually quite beautiful, understanding them is another issue.
the more I understand how it works, the more I loose a sense of ownership.
It is important, and the level of knowledge must evolve to understand more and more
It is a little bit like artisanat and printmaking. you begin with simple tasks, and then you discover its based on more complex dependencies. then you decide to enhance your comprehension and begin doing everything yourself - there's a doomed level youll start printing your own electronic cards -- afterwards it learned me that collaboration is more efficient -- technology is based on society
Yes, but without trying to know everything or you do not get any work done outside playing with Linux
I would love to know much more, but I feel really easly bloked by the technical knowledge
Yes it is, I am in a learning progress of how thing I use work
Yes, defintely important, but it feels like wanting to understand all jazz music that has ever been made, where it comes from etc
Important to know how it works to a level where you can see other logics and possibilities. Maybe that's an infinite tunnel (rabbit hole), but at least have control of machine to use it as a tool for creating, instead of just consuming.
Yes, but recently versions are hidding how things work so it becomes more and more difficult
I always forget to learn it because i'm lost in the tasks i do wth it, it remains a dark pit
yes at least knowing that I can if I want !!!
To a point, you can lose your soul if you dive in too deep (custom kernels is already too deep)
Sometimes I just want to solve something -- make a library work, install something, make the audio work, add a screen resolution... -- but I don't always have the time to learn deeply how it works. I keep notes and recipes for the things I need to solve
Did you buy your machine / chose your system for it's looks?
the computer came empty, so i had to fill it with something - it seemed to be good for start . however, i like ugly interfaces -- i choosed the computer for its resistance -- and added physical decorations
Obviously for it's looks. Ehm. Er. Also, convenience, because many colleagues/friends/fellow travellers have the same machine.
I jumped the thinkpad bandwagon because the laptops are good and cheap and have a reputation for making running linux easier. I like its ugly. The OS itself though I tweak to look nicer.
I chose Thinkpad in the first place (with Windows) in 2006 for its transportability and battery life; then I installed ubuntu on it and the battery life decreased, but I like that it looks and feels as 'a tank'
My wish to have a machine under Linux came from last Relearn, and the feeling of frustration from using a virtual box.
in a way yes! i have used elementary os because of the looks.
what does the "looks" of a machine/system mean ? interface ? the shape of the computer ? choosing a machine is a pain (trying to figure out which parameters is unpleasant for me)
machine not, dual-boot installation I did myself
I would like to, but the choice is poor
Yes; for it's weight and cqpqbilities: processor; grqphics card,...
Looks? All terminals are sexy : ) indeed ;-)
capabilities
Totally, thinkpads are really handsome, and oldskool terminals look more familiar, comfortable and trustworthy than fancy Mac/Win/Google design guidelines du jour
Did you try to change the interface of your computer.
Yes, obviously!
Yes, my most recent re-installation was to explicitly choose and tweak an interface.
It's quite tedious
i just change the gnome settings to a window manager with less "effects" (argh), i think it's called "gnome classic no effects or something like that (a totally ridiculous name)
Yes, I do not like the trend towards smartphone/tablet environments but prefer the 'old' desktop look.
yes, always. for exampl, typically, ubuntu doesnt have things like 'open in terminal' activated by default, so i change things like this. but also i spend toooooo much time fiddling with graphical things like highlight colours, or font sizes
what a fancy thing
canonical designers design in mac os, only test in linux (can't live without adobe)
unity it s wrong--> the fluid interface (big icons)--> keep pace with apple-->"women friendly interface"/always set back to classic when installing ubuntu
removed animations from window manager, made sure terminal has colors.
Yes, as much as I can.
removed some of the graphics :)
yes, XFCE is nice but kind of dry. I customised it a bit for window splitting and stuff
yes, changed to gnome3 (not anymore)
No; I didn't
Yeah, with a minimal window manager (Awesome) with mostly the default settings, which look good enough
Yes. I tried different window managers trying to find one I like. I'm currently using awesome (and enjoying it so far).
Installing a live-stick
There are a few live-sticks lying around containing an Debian 8 image. Use one of these, or create your own!
Download a disk image from the local network / the internet
An 64bit Debian image can be found on the local network
../software/
../software/debian-live-8.1.0-amd64-gnome-desktop.iso
Or on the white USB stick. It's labeled 'debian image 64bit/32bit'
Alternatively you can download an image from the internet:
Debian: https://www.debian.org/CD/http-ftp/
Mint: http://www.linuxmint.com/edition.php?id=190
Ubuntu: http://www.ubuntu.com/download/desktop
Create the Live Stick
Loosely based on debian's FAQ ( https://www.debian.org/CD/faq/#write-usb )
It's the easiest to create these livesticks using linux.
Copy the image you downloaded on the stick using the following command:
dd if=<file> of=<device> bs=4M
where:
<file> is the name of the input image, e.g. debian-live-8.1.0-amd64-gnome-desktop.iso2015-08-19
<device> is the device matching the USB flash drive, e.g. /dev/sdb. Be careful to make sure you have the rightdevice name, as this command is capable of writing over your harddisk just as easily if you get the wrong one!
To make sure you have the right device, unplug the stick and run:
mount | grep "/dev/sd"
Plug in the stick and run agian:
mount | grep "/dev/sd"
The entry added is your device. When copying remove the number. So /dev/sdb1, /dev/sdb2 will become /dev/sdb. As these numbers indicate partitions and we'll overwrite the whole device.
bs=4M tells dd to read/write in 4 megabyte chunks for better performance; the default is 512 bytes, which will be much slower
The copying might take quite a while. If the command is finished unmount your stick and boot from it :)
How to boot from the Live Stick
> shut down your machine
> insert the usb stick with a live-image on it
> start your machine, and hold alt (on mac) (thinkvantage on linux)
> pick 'Windows' --- (why is it called 'windows'?)
> pick 'live (amd64)'
> your live-image is running! your username is user and your password is live
> install the wifi firmware (on mac)
* connect to the Zinneke internet with an ethernetcable, in order to be able to download the firmware
* add 'contrib' + 'non-free' to your /etc/apt/sources.list
sudo nano /etc/apt/sources.list
add the following line --> deb http://http.debian.net/debian/ jessie contrib non-free
exit by hitting Ctrl+X
and then type Y to save the changes
and hit enter
* update the apt source-list
sudo apt-get update
* install wifi firmware b43
sudo apt-get install firmware-b43-installer
* unloading & reloading the kernal module
sudo rmmod b43
sudo modprobe b43
Reroam
focus on elements in the tracks that overflows the topics and try to discuss them?
list of elements on each page : inventory of experiences, glossary... ([[relearn thinking through)]]
(About)drafting
About translation and absences: where is the translations? the blackboard is here, but used differently; the eye of the jenitor (care)
negation: what you chose not to be (as a learning moment)?
time: the temporality of the learning experience
brakedowns: failures in relations and devices
continuity: the 3 year process (the continuity of materials, methodologies, experiences) and also throughout the year (through networks)
relearn as an infrastructure ? in relation to traditional education infrastructure ? are we separating it or not ?
infrastructure in relation with the city
oral transmission at relearn : distinction between memory and archive
+ Notes / friday 21st:::
pad dissemination / concentration :
possibility of all the traks
sketches (and their origin)
translation / remediation (ex: blackboard to pad)
caring / janitorial aspects
negation / not absences but choosing not to be present
time / scheduling
breakdown / failures (in relations, in devices)
continuity / persistence
people? (should people have its own spot here?)
looking at other models / experiences / references
in relation with infrastructure:
(and not only in relation to traditional education)
but tradictional education is full of infrastructures!
For example: city as an infrastructure / can be looked at as a pedagogical environment in itself [scale]
when talking about archives and documentation: Relearn contains also memory // oral transmission and histories and narratives
differences between memory and archive is a process of validation
-
how can we find the way to get to know each other -somehow- quickly?
There were many good ideas when preparing the school, but they need implementation
? we are so much into prototyping that we often miss materialization
//
(from the city track) [[city]]
'methodological toolbox'
aknowledging the fact that you can't reduce the city to one specific aspect
interesting similarity with the recent reroam discussion on 'pseudo-categories'...
need an angle to give depth to the look, without pretending it's exhaustive.. aspects overlap all the time.
HOW & what (s) is going on-- 22.08, 15h
Quantified_Self
Julianne:
(this was unfortunately not captured by the note-taker)
on 'make human'
- we need something that can be automated! as humans, we cannot see 200 python scripts!
about the significant aspect of concrete file -- interest on "MakeHuman": is it relating to the datasets from sensors already? -- that is in progress.
by now staying outside of MH so there is no contamination
the geometry is a bit different - distorted human meshes
quantification paradigm, but self-built
there is very little collected data on the datasets -- thought would be worthy to find other criteria / set new criteria for datasets
also now producing new data (several possibilities, including generatin it ourselves) -- codification must be implemented into the tool for the making of the 3D characters
maybe the problematic point is on one hand the problematization of this paradigm, but on the other hand looking at how it can be better // paradox of criticizing and then also looking for implemenations
one the one hand you want to highlight the paradox, but maybe putting in something different could be interesting (instead: grrrr!)
now in need of address the social aspects of this process
talking about the "celibataire machine" / loneliness and the social >> adress maybe with some possible textual imput
anecdote: the interface shows a character that performs, and there is now this idea of tamagotchization that measures body through steps, glasses of water, etc
would be happy to have more people joining
Data_Mining
similar questions appearing, so they propose to do a common bridge.
not so much on the tools, but on the vocabulary and common problematics -- we can cluster problems
you are too fast! :P
Text_Generation
at the moment people's trying to get going with some of the tools. Ge're getting there more or less, but now have to put it together in order to start common projects
at the pad there is a number of tools
there was quite a difference of skills and knowledges
the group? how did it work? -- kind of organically?
not so much programmers
there is nobody really trying to make some software development
started having a look at the Dada_Engine, install the tool, look at exixting scripts, get familiar with its language and syntax (which is all accessible)
Cath: a pair tried to write their own scrpt learning from the existing ones -- found a corporate page that could work for the Dada_Mining >> Oracle that could work with datamining content: lexic of divination methods
--- maybe join the wirelessness group?
Gijs: looking at some math and neural networks + Markoff chains explitting the ext in words and then select random order of sets that have no semantic meaning but works if you know the talker
Ana & Ricardo also working with Markoff chains -- looked into the code but then went in another way.
Started plaing with a tech that uses M Chain for disabled people who cannot type on a keyboard. Used one interface of eyetracjking. You can put texts in.
Hardware: a gaming interface (joystick), so somehow derivated into a playful item. It is a Markoff Chain with letters (unlike Gij's, wich works with words). it is a visual way that needs to be connected to something that makes more sense; still going somewhere :) started the linux kernel as first source :))
you can actually go backwards too
Sam: also on Markoff chain. started to use patters to start the sentences by some pronouns / as a database(source) using text from a french artist that links sources like french constitution with
Wirelessness
hoping to combine tracks with text_gen: absured machine communication transmitting (...)
yesterday begin downloading the tools for listening to radio using your computer
have this dvd stiks thtat can cover wide ranges of waves
listened around a bit also :)
local frequencies: in bxl you have this emergency system that sends messages to ambulances and ambulances: txt messages that are sent through radio, but are digital data // if you listen is only noise, but you can actually decode them and make them readable
today tried to transmit some stuff
have some arcade transmitters and also some hi-fi
(test not possible at the moment)
will put a transmitter and send upstairs --
transmitting webpages -- nice because actually works!
sending jpgs is another story -- would last for dys >> 100 bits/second
working on a prototype of using glass noodles as fiber optic and transmit through light -- but it's super slow by now -- perhaps with better noodls :P
city
cinematic geography of city -- what means to observe the city as a field of production and as in the production chain somehow
today placed it on track: transform it into a city walk that tries to connect a kind of spots that somehow are exemplars of what they're looking for
project certain forms/formats of city
1)horta fachade: espectacular mode of the layer being instrumentalized. It is a diconstructed facade of a building by horta that has been reconstructed after being demolished and then abandoned due to lack of funds -- through a scanning and 3d modeling process // there is a website that better tells the story
it's interesting because this was found just by walking 500m around the zinneke building
physical artifacts of the building that are hidden but if you scratch, actually find a bunch of layers and details
Dennis: since we're partly people from bxl and partly not, would like to look at places that could be intergrated on the walk with this in mind.
tomorrow morning from 10am, walk into the city with discussion
2)Parlamentarium: spectacular moment on the city, also very spctacular // moment of having videos to explain how/whos
so: examples from propoer cinema to actual phone filmings
3) also: all cinemas (film theaters) that are part of the transformation of the city now.
storage/reverberation of images
MArtino: drop a bit the historical level, but instead encounter stories without the need to look after them: not an extensive mapping of elements (for actually not re-doing, but more assess all the elements and phenomena that are connected through this topic of image production of/in the city)
power infrastructures could be also looked at
commonsense
speaking of adjectives
xml file: the word AMAZING
mentioned twice, first time positivity was 0.8, then it was 0.4.
Wordnet doest divide the two senses, pattern instead makes the average of 0.6.. amazing
so the mathematical average reveals some discrepancy..
studying the math behind the algorithms used to detect meaning from projecting language in the mathematical space
math->language; language->math
grammatical space of the adjectives as core elements of language.
reading scientific papers to understand the rationale behind the workings of this systems..
they seem to break down quite quickly..
algorithms vs human intervention in specifying what means what
loops of humans / algorithms..
what is pure mathematical? pattern?
algorithms has no notion of human beings. just numbers.
human intervention is fit for a starting point, to shape data to fit the algorithmic process (?)
"raw data is an oxymoron"
the act of selecting what to put in, telling the algorithm what is interesting
on one hand you want to offload as much work as possible to the algorithm, but impossible to delegate everything -- the algorithm needs a sort of format to work, this is where the human aspect is necessary
statistics, math, linguistics, culture -- necessary to understand all facets of language
dada engine
-----------------------------
morning conv monday 24th
about the improvised round of presentations:
there was no clear plan, nor timing, it started as a sharing in few minutes the issues/problems/asking help it ended as a presentation with no time limits, showing what is being done-->did it work?
that it was not planned->more observations/sharing failures and attempts than outcomes or provisional plans
sunday meeting: there were diff expectations. (practical issues/ frustrations/ things to change now/ general feedback/ school/ ...)
some issues that are really pressing were pushed aside by abstraction
why to separate the presentation and plenary? isolating reroam?-->becomes abstracter and abstracter
also in the other day presentations there was the intention to keep the two aspects together, but it slides one side or another
group dynamics and group output-->some track already plan to work further, long term engagemnet, no output for presentation (->define output)
idea of dividing in groups and tasks starting from today: there are organizational tasks and issues to be discussed (e.g. presentation).like in the first day soup track, people leave in turns and take 1 hour to work together.
do we want a collective moment? it is collective even in smaller groups
-->it should not be per track-->this is something people joining these conversation agree on but participants perhaps not
*the problem of the making of tracks-->the website/the continuity/dynamics
*same for presentation_>was on the program since beginning, some people perceive it as challenge/ other pressure/ anyway it is acknowledged
*format presentation->
time
closing moment->
----------------------------------------------
Program for tomorrow:
Walk starts at 10
There's food at Poissonerie
Need to get someone to open/close the space, put out the trash tomorrow night
Possible storm in the afternoon
[[dinner]]
Quotes
Ramon Amaro
From ../bibliotecha/Machine_learning_and_racial_profiling_in_data-driven_decision_making.pdf#page=5
(on the circularity of classification)
Gandy theorises that the attentions given to classification, in its naming as relevant/not relevant,
criminal/innocent, and so on, are determined by the problems assigned to each instance of its enquiry.
In other words, types are assigned to associated preemptive actions based on the desired outcomes.
The assignment of relevancy can then be seen as assigning relations of power, and the ownerships of
this power reside in the ability to name a particular instance within certain contexts that require
attention <ref>Becker, K. (2009) The Power of Classification: Culture, Context, Command, Control, Communications, Computing. in Becker, K. and Stalder, F. (eds.) (2009) Deep Search: The Politics of Search Beyond Google. Innsbruck: Studienverlag Gesmbh</ref>
...
What emerges is the quantification of life and social relations that carry potentials to produce other powers and biases within the same spaces that hold great benefit for our social environments. Within this framework classifications are the grounds on which both imbalances and social advances are created and articulated.
*Social Shell
===================
'SSHartre: Shell is other people'
We create *user accounts* on the server for each participant and introduction to using the *shell*
The "shell" or terminal or commandline or TTY, all refer to a way of operating a computer via a textual interface. An interesting history of the [terminal/TTY](http://www.linusakesson.net/programming/tty/ )
TTY = "?"
Talk To You ?
The terminal, yeah?
... http://www.linusakesson.net/programming/tty/ !
Debian (and Mac OSX) is based on UNIX, a multi-user system developed in the 1960s at a time when computers were room sized and extremely expensive machines. Time sharing systems were a radical step that allowed multiple users to connect simultaeously to the same computer and share its resources. As a result, UNIX includes many commands, design features, and idiosyncracies that reflect the social nature of the computer as a shared resource.
The multiuser capabilities of the operating system are a bit like vestigial organs in a modern operating system where often you are the sole primary user of your laptop. The social features of the shell only really become apparent when you use a *remote* login to connect to a *shared server*. *ssh* is a commandline software program that allows you to remotely login to another machine. It stands for *secure shell*. All traffic on *ssh* is encrypted. Linux and mac users have *ssh* already built in. Windows users should download a software like [PuTTY](http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html).
Superuser-------------------
Select one person to play the *superuser*, preferrably somebody that never used the shell before. Those with experience should offer to help.
The *superuser* opens a terminal window and types the command:
ssh admin@10.9.8.7
You will see the following:
The authenticity of host '10.9.8.7 (10.9.8.7)' can't be established.
ECDSA key fingerprint is 42:3f:ec:d1:97:19:19:ea:5f:8b:f9:b8:d4:60:39:3a.
Are you sure you want to continue connecting (yes/no)?
type:
yes
and then the password:
relearn
You should see the relearn server's welcome message.
If things go wrong (you don't see the message), just start again from:
ssh admin@10.9.8.7
You can now create accounts for the other people seated at your table (and also one for yourself!).
Each person should choose a *username* (it should not have spaces) and write it on the IP card and pass it to the super user, who in turn should perform the command:
Now, while logged in as *admin* to the server, the superuser enters the following commands to create a user for each person:
sudo adduser USERNAME
When you use sudo the first time, you will need to re-enter the password "relearn".
You will see:
We trust you have received the usual lecture from the local System
Administrator. It usually boils down to these three things:
#1) Respect the privacy of others.
#2) Think before you type.
#3) With great power comes great responsibility.
Fill in the *administrative questions* if you like (or leave them blank ;)
For the password: give each user the same password "relearn" (they can change it later).
Finally *add each user to the "www-data" group* (use the same USERNAME):
sudo adduser USERNAME www-data
Having all the users in the www-data group allows us to share files with each other using the web server.
That's it, you have made a user login: pass back the card to the user.
when all users have been added, the superuser logs out by typing:
exit
You should see:
logout
Connection to 10.9.8.7 closed.
What to do with your new login----------------------------------------------------
Once you have been given your card back from the superuser, try to login with your username:
ssh USERNAME@10.9.8.7
The first time you connect, you will see the following:
The authenticity of host '10.9.8.7 (10.9.8.7)' can't be established.
ECDSA key fingerprint is 42:3f:ec:d1:97:19:19:ea:5f:8b:f9:b8:d4:60:39:3a.
Are you sure you want to continue connecting (yes/no)?
type:
yes
Use the password "relearn".
You are now connected to the relearn server.
The *who* command will show you others that are logged in, you can speak to other users with the write command, just use their username:
What pts/n means in the list?
"A tty is a native terminal device, the backend is either hardware or kernel emulated. [ what is hardware? a typewriter hardwired to the motherboard?]
A pty (pseudo terminal device) is a terminal device which is emulated by an other program (example: xterm, screen, or ssh are such programs).
A pts is the slave part of a pty."
Try:
write USERNAME
The write command will wait for your input; it reads from *stdin* (or "standard in") which means it reads from the keyboard by default.
Type your message, then hit return and press _one time (on a blank line) Ctrl-D (which means "end of file").
(NB: In OSX: you want to use the _ctrl_ key and not the regular _Command_ key (which splits the terminal. Pressing Cmd-Shift-D will undo this)
Note: Press it just once (at the start of a blank line) when a command (like write) is reading from stdin. If you press Ctrl-D again (at the normal shell prompt) you will logout from the server. To login, you will then need to start again with the ssh command.
To check whether you are still logged in, your prompt should look
automatist@relearn:~$
To prevent messages from appearing on your screen
mesg n
(thanks! how to put them on again? mesg y?)... try man mesg (but y!)
Command History
-----------------
You can generally use the arrow keys to go back and forth in the history of your commands. Try it!
Read a manual,
--------------------
Try some more commands:
date
man date
man man <3
figlet hello
man figlet
When you use the *man* command you enter a program to read the manual of a particular command; you can scroll with the arrow keys and you can press _q_ to quit it and return to the terminal.
When you start figlet without any options, it also reads from *stdin* (standard input). By default this is the keyboard; note how it responsds as you type. To stop, press Ctrl-D on a line by itself.
Programs often take options, typically preceded by the "dash" character (-). Like:
date +%A
The explanation for all the options of a program are given in the man page:
man date
Promiscuous Pipelines
-----------------------
The special character "|" is called the pipe and can be used to connect multiple commands.
Try these commands:
date +%A
date +%A | figlet
whoami | figlet | write SOMEBODY
Password
--------------------
You can change you password if you want using:
passwd
Dinner
specific things that 'worked'..
what i wanted to do didnt happen. many other things did...
presentation of what one had in mind.. where to start?
--
is it auspicable to concentrate on shared layers instead than personal ones?
as the personal ones can be endless.
proposal of building a shared glossary. to contain the vocabularies that emerged..
presentation element in the glossary could be a place where to place thje doubts..
if everybody has an in issue with presentation, lets write it down
glossary of sentiments towards recuring things
such as what does THIS group feel towawrds 'presentation'.
inventory of issues, that are not named?
two ways, pushing and pulling.
people from the tracks push issues, items..
or hang some questions to look at..
question of the track, putting element.
look back at what we did, what worked and what not.
but then if this is just on tuesday, you don't really have the time for responding to it.
continuity.
last year similar situation, some time to discuss how hte school worked / didnt work.
very related to the issue of the next school (or not
what worked what not? well, the morning moments didnt.
how to think about the school while you do the school.
---
explain why some things happen and what not?
*thursday morning, a set of five scripts. tools network, etc. instead of run of presentations. instead of personal presentations.
*why start at 9,30 and stop at 18.
*why all in the same room
lot of design, let's talk about it.
also undesigned, like "mixeity".
"for example we arrived from twitter".
"yesterday I couldnt come in cos the code was different"
"why there was no presentation?"
through the pad is kind of impossible.
welcome moment was missing. there was by the "DHCP" server.
housing is a most welcoming moment. the autarkic choice of airbnb reveald problematic.
--
could you do without tracks?
from conversaitons in preparations.. could we avoid tracks?
in a practical way it would always be not call a track a track...
what's the trackness. the structure of tracks varies wildly..
how to collect things -> collecting things in a way that doesn't require an outsider to dig through the pads etc.
matter of interface?
FS: recording vs shared memory (of experiences)
there's a difference between the two.
ergo: if an outsider reads the recordings there won't be the embodied experience of the issue
H: track preparation perspective: the tension between preparing a lot but also wanting things to 'emerge'
N: there wasn't a moment of looking back on what was done and what happened.
A: the feedback also needs time, it takes time to process what happened and to formulate an opinion on that. That also makes it difficult to reflect on these things in the heat of the moment
FS: last year reflection of the school lead to a conclusion that next edition would be differen. this edition's preparation was a lot about incorporating those ideas but now it seems that the reflections on the school are again being pushed towards the back.
F: what is hte proposal for *now*
FS: can we have this discussion now at the moment? concretely stating what are issues that emerge, what things need to be worked on, where do we need to shift
an *unstructured* / *unforced* explanations of the workings of the school follows:
J: why did we have the first morning hte way we had it (with the 5 tools etc), there are reasons why the door has two code, there are reasons why etc
What are there reasons why there where no 'proper' introductory introductions etc. For people outside the network that was weird.
J: Length was one of the reasons (50 people presenting) 2: The 'presentations' where shared on the ethercalc
FS: the emails where not 'this is me and tihs is what I've done" rather; "this is why i want to be with you"
J: didn't realized it could be harsh for newcomers
The housing situation was also a form of introduction
N: the 'organizations', networks, behind organizers where also not made explicit. although they definately influence the social dynamics
FS: coming from another method of organizing; struggle with the non-welcoming etc, the two door codes
*beerrrun*
T: how much organization/conversation is there between summers? conversation on listss etc?
M: the list is not being used as such; its more about interpesonal relations. people meet on a frequent basis and this is hwere the thinking happens
F; the pad a part of the public conversation which I followd
M; all the time we are trying to avoid participant/organizer division and we should expect participants to want to take over more
FS: how can we get rid of the 'track' structure? becuase it organizes the flow of people in very particular ways
M; it is also how it is presented on the website
H: it would've been better to lose the idea of the track to also welcome 1 day prepared contributions etcc
F: issues to discuss
F: 1: presentation
P: approval from your peers!?
F: 2: documentation
AN: parenthesis(the question of git!!sharing, was it/is it missing)?
AN: when is finished, I have my docu in the repository and look at it, try to understand it, i need it (but not as if i DONT have my back of files I am the seddest woman in the univers)
FS: have documentation and have the struggle to read it (at home, local server)
P: sharing -> the thing is not to do present a presentable project, but rather presenting a way of things that happened and which can continue? its more about describing the track rather than a workshop outcome?
MM: is the form of 'tracks' still a given for the last two days? b/c some tracks have become more guided, where that is not always so desired..
FS: when overlaps are strategically planned to coincide it works well to have overlaps but may also work w/ organizers
M: people initiate tracks for a reason (enthousiasm) , if you leave don't you also take the energy of the general track out?
N: different dynamics in tracks
H: You should not leave people alone behind their computer. Difference in preparation, if there is more preparation people can be more independent.
A: It takes time to get through tools, before asking: Now what. Good to avoid centripetal (?) forces
FS: Time? Summer school?
AL: How to bring Relearn back to formal education. Often tried and failed. What to do with this experience when not at Relearn
R: Different when you organise; it is a longer process; so everyone needs to have a chance to do it all the time, so it is not an exception
M: Some people want to have just one week, others want continuity.
N: Newcomers ...
R: Is it all about way of speaking, presenting? Frustration: try to get rid, but it slips back in?
N: Is it different from last year?
FS: Yes.
M: Could we think about how to end the week?
FS: Options??
A: We have an afternoon? What is the plenary?
MM: What I did? Or: How did I relate to the school?
A: Finding a way to ...
An inventory of dealing with the Presentation issue:
Denial (no presentation), reorganising, presenting to small groups (many times; not to everyone -- reuse morning script), tracks/groups presenting each others work, using a set of questions to answer: What did you take ... how does it live on ... People will get different stories.
There should be a moment of showing what you did, but how to do it. 5 times 20 minute moments ... what can be done. Some plenary, not all?
No plenary, means no overview?
Thinking through ways ... different things: experiment with plenary of presentations, but still needing a plenary for closing the school.
let's try some wild options, for once.
rotation is the way to go! we'll need to script it; how to do it (and when??)
System script really worked, the questions. This could work for end-presentations as well.
*SSHaring
=============
(how do you pronounce it ?)
sch-sch-scering ?
sch-sharing
haring?
ess-ess ha-ring?
the sharing machine as a garden @}----LEAFfill it with cr*p and watch beautiful things grow
==========================
server = 10.9.8.7
Upload (a) file(s) that you brought with you to the server.
Having a local server can mean many things. It means we can share files with each other with the convenience of a "dropbox" but without uploading files to servers halfway around the world (with not just technical but also potentially legal, economic, and other social consequences ) -- just to let someone sitting next to us have a copy. The server is also a shared (proto) publication; more than just a temporary holding place, the collection of files is a first step to a collective act of writing -- so the gardening of the space (organising, (re)naming, moving files, may be as important as adding them in the first place).--->care
A fundamental thing about file sharing, though, is also the care that goes with preparing the material. Naming the file, putting in the right folder or creating the folder if it's missing; they are not trivial things.
File Drop----------
You can drag and drop files onto pages of the web browser at: ../. You can also put files in specific folders. If you want to later change their name or location, you can use ssh (see below).
(you can see your upload process in your console)
sharing machine as a library: bibliotecha-------------------------------------------------------
For sharing electronic books (pdf, epub, ...), there's a special folder called bibliotecha. Digital books placed here are visible through a web interface of a free software project [Calibre](http://calibre-ebook.com/). [Bibliotheca](http://bibliotecha.info/) is a framework to facilitate the local distribution of digital publications within a small community.
To add a book in the bibliotecha, you need to do it via the command-line:
calibredb add -a AUTHOR -t TITLE -TAGS --with-library /home/www-data/bibliotecha filena.me
for example:
calibredb add -a "Jan Masschelein and Maarten Simons" -t "In defence of the school" -T diseducation --with-library /home/www-data/bibliotecha Jan_Masschelein-Maarten_Simons-In_defence_of_the_school.pdf
ssh----------
When you ssh to another machine, there are a number of commands to:
* Look at the files + folders
* Create new folders
* Remove files & folders
* Manage the *file permissions* that control access to your files in the shared space of the server
To add a folder or move files around, you need to connect via ssh to the server...
you can make new directories (mkdir new_dir)
move files around the folders (mv files new_location)
Summary of File commands------------------
pwd print working directory: Show the current folder you are *working* with
ls list: show the current files in the *working directory*
mkdir images make directory: make the directory called images (in the working directory)
cd change directory: move to another directory when used by itself it jumps to your home folder
cd images Attempts to enter a directory named *images* in the working directory, this is a relative path (as it does *not* start with a slash) it is considered relative to the working directory
cd /home/www-data Change working directory to /home/www-data this is an *absolute path* (starts with a slash)
touch *somefile* Pretend you just edited and saved this file, creating a new file if necessary
cat *somefile* Dump the contents of a file to the screen to read|
less *somefile* A pager: shows the contents of a file with the ability to scroll (using the arrow keys), press *q* to quitSSH can be used like ftp to move files to and from a server. It's more secure than ftp though as your password and the contents of the files transmitted are encrypted.
scp-----------
### scp
With the terminal, try commands like the following (where *myfile* matches the name of a file on your machine, and *username* and *server* are your username and the address of the local server).
scp myfile username@server:
Copies myfile to *your*ls
home folder on the server. NB: The colon at the end is essential as this makes the address a file location. If you forget the ":", the scp program will copy the file to another file named "username@server" -- not at all what you wanted!
scp -r folder username@server:images
Copies a folder (recursively --- meaning contents included) to a folder named "images" in you home folder on the server. Accesible also in the browser via: ../ , act responsibly ;)
scp -r folder username@server:/home/www-data/
Copies a folder (recursively --- meaning contents included) to an absolute path on the server (the root of the webserver).
DOWNLOAD FILES FROM SERVER TO YOUR COMPUTER
don't be on the server and
scp username@10.9.8.7:path/to/file path/to/your/download/folder
Permissions--------------
When you
ls -l
Shows ...
-rw-rw-r-- 1 automatist www-data 0 Aug 20 08:42 hello
This file is *owned* by automatist, belongs to the the "www-data" group, has 0 bytes (it's empty) and was created on August 20 at 08:42 in the morning ;) The owner and group have read & write access, others can just read the file.
You see not only the names of files, but their permissions. Permissions determine what you can do with a file. There are three main things:
r: read (see the file)
w: write (change the file)
x: execute (run the file as script, or for a directory -- to make new things inside of it)
In addition, there are three sets of permissions for:
u: the user (or origina "owner" of the file)
g: the *group* of the file
o: for *others* (everyone else)
You can use the command *chmod* to change permissions as in:
chmod g+rw hello
Means allow the file's group to read & write the file named hello.
The chown command allows you to change ownership of a file:
chown automatist hello
Make hello owned by automatist. chown can also be used to set the group:
chown automatist:www-data hello
I'm not sure I understand why groups are necessary? Can't a file just be owned by a single file be a single user? What is the advantage of setting a group owner? Does it give ownership of the file to all people in the group?
There is no group owner, the above example sets the file to belong to user automatist and group www-data. Anyone in the www-data group can access it if the file has the group read permission (see the chmod example above) and write to it if it has the group write permission.
GUI-------------
Generally, anytime you have ssh access to a server, this means that you can use *sftp* (secure file transfer protocol) to send and receive files from that same server. *sftp* is built on top of the ssh protocol. There are different graphical programs that give convenient access to working with files on a remote server.
The window manager gnome supports a "Connect to server" feature that directly allows sftp connections, just use the form:
sftp://USERNAME@10.9.8.7
Cyberduck-----------------
On Mac OSX and Windows, [cyberduck](https://cyberduck.io/) is free software that provides a very helpful graphical interface to drag and drop files to and from a remote server. You can also *edit* files with an editor on your local machine (the program automatically uploads changes when you save them).
Installers for cyberduck are available on the local server:
* ../software/CyberDuck-4.7.2.zip for Mac OS X 10.7 64 bit Intel
* ../software/CyberDuck-4.7.2.zip for Mac OS 10.6
* ../software/CyberDuck-Installer-4.7.2.exe for Windows
Filezilla is a nice alternative that works well in Linux systems too. +1
And a good code editor:
* ../software/SublimeText2.0.2.dmg Mac OS X (freeware)
* ../software/SublimeText2.0.2x64Setup.exe Windows (freeware)
Note: Sublime text is not freeware, you are supposed to pay for the license. It will keep working if you don't, which is why it's confused with freeware.
A better code editor that doesn't hurt your freedoms is Gedit. Comes with Linux systems running Gnome, and there are also Win/Mac versions:
* ../software/gedit-3.2.6-3.dmg (mac)
* ../software/gedit-setup-2.30.1-1.exe (win)
There is also Atom, if Gedit is too simple and you miss the bells and whistles of Sublime Text:
* ../software/atom-windows.zip
* ../software/atom-mac.zip
* ../software/atom-linux.deb (for Debian-based distros like Ubuntu, Mint, Crunchbang)
* ../software/atom-linux.rpm (for RPM distros like Fedora)
Another editor that is already intsalled on your system is vi
sshfs---------
Another option is to use *sshfs* to mount the server like it was a local hard drive or USB stick. In Debian you can:
sudo apt-get install sshfs
and then:
mkdir mnt
sshfs user@serveranme: mnt
Will connect your home folder with the local (initially empty) folder named mnt. The great thing about *sshfs* is that it allows you to use any software (commandline or graphical) with files on the server as if they were on your local computer.
Generating an ssh key------------------------
To make it easier to login to the server, you might want to generate an ssh key.
ssh-keygen
(run this on your own machine, not while you're logged in the relearn server)
Generates the ssh key. An ssh key has a *private* and a *public* part, the idea is that you never share the private part, and do share the public part -- and the software uses the fact that the two parts can be checked if they "fit" together.
- can we leave the passphrase blank?
A: It is possible, but not safe. If someone gets access to your machine they can copy your private key and get full access to all your servers. With a passphrase you still have one layer of security.
- is it possible to edit the passphrase after i created a ssh-key?
Great question, I don't know :-(
is it possible to delete a key?
Sure, the keys live in your ~/.ssh directory (id_rsa is your private key, id_rsa.pub is the public key)
The command:
ssh-copy-id USERNAME@10.9.8.7
Will copy your public key to the server (it adds the contents of your "~/.ssh/id_rsa.pub" file to "~/.ssh/authorized_keys" on the server). If this works, then you should be able to login to the server without typing your login password.
Server name shortcut--------------------------
Sick of writing 10.9.8.7 all the time? Make a shortcut in your ~/.ssh/config file adding these lines:
Host relearn
Hostname 10.9.8.7
User YOURUSERNAME
Now, instead of ssh user@10.9.8.7, you can just type ssh relearn . Copy your SSH keys (see above) for a seamless, streamlined and refreshing command line experience(tm).
Fantastic!
note: in case your system asks you to enter the password to connect with your private key, enter your passphrase, not your system-password, nor server-password.
Make friends with your ssh-agent!------------------------------------
Sick of typing your passphrase every time you want to login or copy something? There is a nice tool running on your system called ssh-agent, which can keep track of your keys for you and remember them to skip the passphrase step while you're logged in.
Try typing ssh-add and input your passphrase. Now try connecting or copying a file, and it should do it passwordlessly! (word of the day)
*Links & Tunnels to the outside
================================
While the relearn network is autonomous and not connected to the Internet, the relearn server is connected to two networks -- the relearn network as well as the Zinneke network that has access (via belgacom) to the Internet. One way to reach the public Internet is via the server & ssh.
links (the program)---------
Start links by typing the command 'links' while connected to the server via *ssh*. Links is a interactive program (like man or less) and takes over the whole terminal. Press the 'g' key to *go* to a specific address. Use the up and down arrow keys to move through links and press return to follow links. The left and right arrow keys move back and forward in your history. Press the 'esc' key to open a *menu*. Press 'q' to *quit* links. Try 'man links' (from the shell) to get more information about how to use links.
ssh tunnel--------------
Now that you have an ssh account with the server, and since the server is connected to the public Internet, you can use your ssh connection as a "tunnel" to reach the outside network. First, from the terminal, start an ssh session as before but with the -D (dynamic) option with a port number. This number will be your local connection to the tunnel.
ssh -D 4321 username@10.9.8.7
Then in Firefox (or other browser), you need to configure your connection to use a SOCKS proxy. In Firefox, this option is found via Preferences -> Advanced -> Network -> Connection: Settings...
MAKE SURE YOU CLICK Remote DNS!
FILL IN THE PORT YOU DEFINED ABOVE (4321 in this example)

../images/FirefoxSOCKS.png
This way of connecting is interesting for multiple reasons. When you tunnel via ssh, you're network traffic is encrypted. In this way, if you are using a hotspot that you don't fully trust, you can make sure that all of your traffic is encrypted. Also, your network traffic will appear as if it originates from your server; so by connecting to an ssh server is in another country, a tunnel could be used to circumvent filtering and blocking based on your geographic/national location.
HOW TO SAFELY QUIT USING SSH TUNNING WITHOUT BLOKKING THE PORT??
aka...> $bind: Address already in use
Socks Proxy on your terminal commands
You will need internet with cable, or your smartphone access point to download the proxychains app
on linux:
sudo apt-get install proxychains
then edit the file
/etc/proxychains.conf
add your tunnel port, look for the line [ProxyList]
socks4 127.0.0.1 YOURPORT
on Mac:
use brew to install
brew install proxychains-ng
create on your home folder .proxychains folder
mkdir .proxychains
download the file
cd .proxychains/
wget https://raw.githubusercontent.com/rofl0r/proxychains-ng/master/src/proxychains.conf
edit tunnel port (at the bottom) of the follow file .proxychains/proxychains.conf
socks4 127.0.0.1 YOURPORT
How to Use
on linux
proxychains YOURCOMMAND
examples:
proxychains apt-get update
proxychains ipython
proxychains python script.py
on mac
proxychains4 YOURCOMMAND
examples:
proxychains4 apt-get update
proxychains4 ipython
proxychains4 python script.py
*BLESS YOU*<3
Resources------------
* [SSH Tunnel + SOCKS Proxy Forwarding = Secure Browsing ](http://embraceubuntu.com/2006/12/08/ssh-tunnel-socks-proxy-forwarding-secure-browsing/)
* [The black magic of ssh](The Black Magic Of SSH _ SSH Can Do That_-SD.mp4) [source](https://vimeo.com/54505525)
* [http://blog.trackets.com/2014/05/17/ssh-tunnel-local-and-remote-port-forwarding-explained-with-examples.html](http://blog.trackets.com/2014/05/17/ssh-tunnel-local-and-remote-port-forwarding-explained-with-examples.html)
* [SSH: The definitive guide](http://csce.uark.edu/~kal/info/private/ssh/index.htm
*Minestrone
Minestrone is a traditional Roman soup that consisted mostly of vegetables, such as onions, lentils, cabbage, garlic, broad beans, mushrooms, carrots, asparagus, and turnips. This version is a bit simpler, but basically follows the same method and combination of ingredients.
The goal is to make 2 large pans of soup at the same time = roughly 1.5 bowl per person.
Cutting and cleaning vegetables & herbs can of course be done in advance, but just-in-time is great as well. Just be sure the vegetables aren't added too late. Cross off tasks that are done!
All ingredients need to be divided in equal parts over 2 pots.
Ingredients----------
onions, chopped
scallions, chopped
garlic, roughly chopped
fresh tomatoes, washed, diced
parsley, washed and roughly chopped
bouillon cubes, crumbled
celery, washed and sliced
leek, washed and sliced
carrots, peeled and sliced
cauliflowers, washed and divided into small florets
green beans, washed and halved
courgettes/zucchinis, washed and diced
white beans, rinsed
canned tomatoes
penne
bayleaves
mixed herbs
salt
pepper
parmiggiano or feta
bread
50 dishes, cleaned
50 spoons, cleaned
2 ladles
10 tables, set
Method----------
11:00 [step 1]
Saute chopped garlic, diced onion and scallion in olive oil until lightly colored
As soon as done: add diced fresh tomatoes
11:30 [step 2]
Fry tomatoes, onions, garlic until they start to dissolve
Add tinned tomatoes per pot
Add half of the chopped parsley
12:00 [step 3]
Add: chopped celery, half of sliced leek, sliced carrots, cauliflower
Fill pots up with boiling water
Add 4 cubes of crumbled bouillon per pot
Add 2 tablespoons of mixed herbs per pot
Add 3 bayleaves per pot
12:30 [step 4]
Check that the soup is boiling softly
Stir gently
Add green beans
Add diced courgette
13:00 [step 5]
Check that the soup is boiling softly
Stir gently
Add three hands of pasta per pan
Add rinsed white beans
Add second half of sliced leek
Check seasoning, and if all ingredients have warmed through
Set: table
Check that the pasta is cooked
if so :
Remove bayleaves
Add second half of chopped parsley
Add salt, pepper if needed
13:30 Lunch ready!
Manual etherpad dump: [[AllEtherText]]
Hi!
On this pad, a computer is using Dasher to generate text.
This is mostly random but we want to understand how things come about using this generation method.
Tools:
Dasher, eye-tracking for typing:
https://en.wikipedia.org/wiki/Dasher_%28software%29
http://www.inference.phy.cam.ac.uk/dasher/
Generated texts from day 2: ../text-generation/text-and-drive/generated_texts
How to feed Dasher with any corpus
Using the "Import Training Text" option did not work for us, it hangs at 100% progress. We found another method, though.
Ensure that you have a ~/.dasher directory.
Copy over an alphabet file from /usr/share/dasher to ~/.dasher . There are alphabet files available for many languages, just copy the one you will be working with (e.g. alphabet.french.xml).
Also copy your corpus to ~/.dasher . Your corpus file is just a text or collection of texts that Dasher will learn from. The file name is your choice.
Edit your alphabet file (and maybe rename it since you'll be using one for each corpus), and change the following things
alphabet name: The name that will appear on Dasher's language selection interface
train: The filename for your corpus file
groups and characters: these are the characters which will appear on Dasher. Feel free to remove numbers, punctuation and other that you won't need. Remove the uppercase group to get only lowercase output. Accented characters show up as numeric HTML entities -- see here for entity codes http://www.w3schools.com/html/html_charset.asp
Now run Dasher, you should find your new alphabet in the language selection dialog.
It is not necessary to pre-process your corpus file for usage, but there are some details on the inner workings of Dasher here: http://www.inference.phy.cam.ac.uk/dasher/Training.html
Setting up the OS for Spacedasher
Install antimicro to set up mouse control with a USB gamepad
Replace the default arrow cursor with a spaceship sprite (we spent hours trying to install a separate cursor theme, but it's a real pain; a lot easier to just edit the current one)
To turn the PNG image into a cursor file, see http://www.ehow.com/how_5026012_make-cursors-file-ubuntu.html
Spaceship sprite source:
http://orig15.deviantart.net/6a58/f/2010/318/2/b/spaceship_sprites_by_pavanz-d32tpys.png
Visuals for generated text:
* getting image search results for the letters of the alphabet with Firefox plugin DownThemAll.
Example url: https://duckduckgo.com/?q=M&ia=images&iax=1
To try:
- gliph fonts http://zurb.com/playground/foundation-icon-fonts-3
- Noto Sans has emoji support. Dowload: https://www.google.com/fonts/download?kit=kYO3G_AjvXSOqWa7MrnTaFtkqrIMaAZWyLYEoB48lSQ
Taking care of the space, each other and the building
(note that most of the tasks imply two or more people)
Door code: 1341
Smoking: Please smoke in the courtyard downstairs to keep the passageways free of smoke
Opening and Making Coffee
make coffee in the morning and make sure the pots are (re)filled throughout the day
keep tidy the coffeecorner in big space
Notes for TeaCoffee Makers : important to be 2, start from 9.00
We didn't decide yesterday but guess TC Makers are also supposed to take care of the refill - TC corner in the main room during the day
We also started a shopping list course in the kitchen - - > could be of help for the ones who do the (morning) shopping.
If coffee is too strong, tell it ! (or add water ah).
20/8: cath & natacha & roel
21/8: ana & ricardo& kym
22./8: sam &juliekd
23/8:thiago & radamés
24/8 manetta&Jules
25/8: anna
The morning shopping
20/8: Natacha
21/8: Andrea
22./8:
23/8:
24/8:
25/8: an
Bibliotecha Librarian
Organizing, tagging the things uploaded to ../bibliotecha/
20/8:martino
21/8:
22./8:
23/8:
24/8:
25/8:
Refreshing toilets
20/8: martino
21/8: an
22./8:Raphael & Louise
23/8:anita
24/8:Wembo
25/8:andrea
Time Keeping
20/8:andrea
21/8:
22./8:
23/8:
24/8:
25/8:
Closing Zinneke
To close down the space a few things need to be made sure of:
Windows closed + locked (especially in the basement)
Lights off
20/8: Raphael & Louise
21/8: Anne
22./8: Emile
23/8:
24/8:
25/8:
Collecting receipts
daily book keeping (2 people all week)
femke+
Taking out all trash bags on sunday night
Check yellow or blue with Christophe from Zinneke
Cleaning up after (26/8)
Anne, Sinzi, Roel
INSTALL YOURSELVES INTO RELEARN
EVERY EDITION THE SAME STORY. HERE WE ARE, AGAIN. PADS PERSISTENTLY PROMISED US TO SOLVE ALL OF OUR PROBLEMS.
BUT WHILE PADS MULTIPLIED FOR THIS PURPOSE, PROBLEMS MULTIPLIED ALONG THE ETHER:
[if links do not work, wait next session to access outerwebz, hopefully]
an inventory of experiences:
- annotating/note-taking -- and the tools we use for that (and how notes stop being notes to something but become self-standing since we abuse of pads) source: http://pad.constantvzw.org/p/relearn_thinking_through
- an experience of break-down
Not having thought of people arriving without machines
- an example of a broken tool that works nevertheless
pad's timeslider
an inventory of absences:
- an example of a an element you normally find in traditional education that you expect to be missing in relearn
- latences (translation) -> things that are present but were translated / their medium changed somehow (e.g.: the blackboard into the pad)
a collective glossary:
- profanation: "The term "profanation" has been proposed to describe the moment in which a tool, knowledge, skill can be put out of its normal functioning, rendered inoperative, and through this can be opened up to other uses, and made again common good. In a sense, it could be considered very similar to a notion of "hacking". source: http://pad.constantvzw.org/p/relearn_thinking_through
- trinary logic or binary alternative (the neutral) source: http://pad.constantvzw.org/p/trinary
- what is an infrastructure and how it is related to reproductive tasks and/or caring practices [[taking care]]
- compare function and efficiency
- what is good technology
an inventory of questions:
- "in which way does a file system relate to an office?" source: http://pad.constantvzw.org/p/relearn_2015_proposals
{- (tapping their own forehead) "We have told you: this place is now a school.
Q: what makes a school? / What do you mean a school? Where are the janitors? And I didn't hear the bell..."} source: http://pad.constantvzw.org/p/relearn_thinking_through
- HOW do we call this a school?
- is Relearn an island of time in between life?
- did you ever look under your (school)desk?
- what conforms a "participant"? network of human+tools+knowledge+presence...?
- playing with inputs and outputs--> profanating while mantaining blackboxes? is it possible?} source: http://pad.constantvzw.org/p/relearn_thinking_through
- "metapads. what about using the provided timeslider? then problem is that its passive." source: http://pad.constantvzw.org/public_pad/relearn_2015_tt_intro
an inventory of tensions:
- {documentation, memory, temporality
- expertise, experience, transference
- tools, practice, affordance, materiality, infrastructure
- informal/formal/non-formal education, validation
- collective learning, self-learning
- conviviality, appropriation, control, hosting
- dissensus, privilege, empowerment
- fiction, speculation, interrogation, projection} source: http://piratepad.net/learningextitution
- notetaking is not sharing is not documenting is not archiving is not publishing source: http://pad.constantvzw.org/p/relearn_thinking_through
To further read/roam through this questions:
http://pad.constantvzw.org/public_pad/relearn_2015_tt_intro
http://pad.constantvzw.org/p/relearn_thinking_through
http://pad.constantvzw.org/p/install_yourself_into_relearn
http://relearn.be/2015/r/Reroam_material_repository
[[meta-relearn]]
...IT SOULD HAVE FELT AS SOFT AS A PERSIAN CARPET, BUT IN THE END... (see timeslider)
FOR THE FOLLOWING DAYS, THOUGH, WE'LL KEEP TRYING: EVERY MORNING, *FROM 9:30 ON*, AROUND THE KITCHEN TABLE
NOW: go on and keep the documentation rolling
Thursday 20 AUG, day 1
09:30 - 10:30 Breakfast+intro+tour of the space
10:30 - 13:00 Introduction of tools & functioning
13:30 - 14:30 Lunch (at Zinneke)
14:30 - 15:00 Dishes!
15:00 - 18:00 Introduction of worksessions
***in between: there are drinks on the stage, feel free!***
introduction of tools & functioning
all together
[[Network]]
[[Etherpad]]
group 1
[[Minestrone]] --> step 1
[[Linux]]
[[Social shell]]
[[SSHaring]]
[[Tunneling to the outside]]
group 2 [[Group-2]]
[[Linux]]
[[Minestrone]] --> step 2
[[Social shell]]
[[SSHaring]]
[[Tunneling to the outside]]
group 3
[[Linux]]
[[Social shell]]
[[Minestrone]] --> step 3
[[SSHaring]]
[[Tunneling to the outside]]
group 4
[[Linux]] ---> [[Group-4]]
[[Social shell]]
[[SSHaring]]
[[Minestrone]] --> step 4
[[Tunneling to the outside]]
group 5
[[Linux]]
[[Social shell]]
[[SSHaring]]
[[Tunneling to the outside]]
[[Minestrone]] --> step 5
introduction of worksessions
Text generation project
How I Learned to Stop Worrying and Love the Algorithm.
Language practices are often ritualistic, what makes them predictable and open for automation. Legal, administrative or political language have magic-like qualities. Their words create realities or make things happening. Do they retain this quality when they get automated and become algorithmically reproducible? What qualitative change undergo such language practices when automated?
[This track is co-organised in close collaboration with the Training common sense-project and will partially overlap.]
http://pad.constantvzw.org/p/text_generation
[[text_generation]]
Training common sense
Where and how can we find difference, ambiguity and dissent in pattern-recognition?
What kind of assumptions do we encounter when valuating information from the point of view of an algorithm? In what way does the introduction of pattern-recognition allow (or makes impossible) difference, ambiguity and dissent? Through exploring the actual math and processes of pattern-recognition together, and by studying and experimenting with software packages (Pattern, ...), methods and reference-libraries (WordNet. ...) we would like to understand better what agency human and computational actors might have in the co-production of 'common sense'.
[This track is co-organised in close collaboration with the Text generation project, and will partially overlap.]
[[training-common-sense]]
http://pad.constantvzw.org/p/commonsense
Wirelessness
When speaking about invisible technologies radio is perhaps both the most invisible and yet the most present. At any given moment the air is filled signals ranging from cell phone packets, the chatter of bus drivers, commercial radio stations, wireless internet modems, airplane tracking signals, satellite broadcasts and much much more. The radio wave has interesting properties, signals can propagate across the earth, reach us from outerspace and transcend political borders. These signals, while physical and legistlated, are difficult to 'own' and in a way the 'hertzian space' can be interpreted as a commons, like the air we breathe and the water we drink.
[[wirelessless]]
http://pad.constantvzw.org/p/wirelessness
Data-/Network-/Film-City
The city is work of fact and fiction. It is the subject, protagonist and background of an omnivorous and polymorphic narrative. It is a collective piece written by the storytelling of novelists, historians and journalists. Its textual production is also found in daily diaries, in technical and bureaucratic reports, in advertisement and propaganda. The city is an anthology continuously integrated, revised, quoted and translated, reverberated in oral and non-verbal accounts, told in pictures, set in movies and combinations of old and new media. The city produces stories and is produced by stories. Narration represent both an inextricable substance and an essential dimension of urban reality.
[[city]]
http://pad.constantvzw.org/p/city
New visuals for quantified self data
The culturally con-structed body would be the result of a diffuse and active structuring of the social field. (Butler, 1989)
This topic proposes to explore the functioning of Social networks based on collected physical data, self tracking and health monitoring as they are expanding very much, and propose a very specific social context based on a quantified view of our bodies.
[[data games]]
http://pad.constantvzw.org/p/data_games
Other possible transversal worksessions
On Trinary Logic, Water Computation and other abnormal approaches to computing
http://pad.constantvzw.org/p/trinary
[[trinary]]
Reroam II
[[reroam]]
http://osp.constantvzw.org:9999/p/reroam
Improvisation, for humans and automatons
[[improvisation]]
http://pad.constantvzw.org/p/improvisation
it started as a joke on postmodern theory, got accepted in academic articles. Later same happened with computer science and mathematical articles. -> shows how language functions in specific social settings,
look at algorithms, see how they work
computed generated erotic texts--can't tell (stereotypical tone, more easy to generate)
study "grammar", looking at code
everything predefine, nevertheless seems human made..(=realistic?)
algorithm learns to speak (shakespeare)-->feeding a lot of text, build math model, optimizing
www.youtube.com/watch?v=qv6UVOQ0F44 computer learning winning/playing video games
masked "types" like in commedia dell'arte
-------------
starting from tools, start playing
explore tools in different ways (don't need to know programming)
computer generated bullshit
text-mining/data-mining-->can use pattern library too
"the annotating has been done long time ago..by shakespeare"
responding to computer generated spam
/ an inventory of experiences
"they looked at the website, they didn't read it" nuclear w. parody. exploiting ritualized language situations
/ an inventory of absences
/ a collective glossary
ritualized language situation
/ an inventory of questions
/ an inventory of tensions
automation, activism
**********************************************
21st August
round of presentation/ideas:
Gijs: Generate texts from / for politicians
Anna: From Barcelona, working with code for interactive installations. Interested in the track to be able to generate content which can pass a turing test. Also can feed it to other tracks? Can we generate text for politicians based on "langue de bois" text? Can this text be used in politics to get to an agreement? Therefore, can we replace politicians by politic bots?
Ricardo from Porto : interested in text-generation with a Dada-ist approach. Emulating interest ; create system to replicate, rather than passing Turing test like humans. Also worked with automated lay-outing these generated texts to turn them into objects.
Ana Isabel: also from Porto, designer. Collaborating with Ricardo. Has been experimenting with text. Have Portugese material, also other material they can share. Fado lyrics, texts from Parlement, also done experiments with newstitles.
Loraine: Observing
Wembo: Graphic designer, previous project was a Prejudice Generator (executing/speaking without thinking). Grammar structures for prejudice, local variations. (combination of different populations to make the generated text more and more absurd)
Prejudice different from place to place, learning to be as absurd and offensive as human beings
Jara: Language research group, contemporary poetry, in Madrid. Worried about depolitization of the new conceptualists, and interested in tech approach of their work. Euraca (?) group. Present languaging. Mediation through technological layers, as well as contextual or oral ones. Trying to learn simple methods of text manipulation [euraca: about https://seminarioeuraca.wordpress.com/about/ // conceptualismos yankis: https://seminarioeuraca.wordpress.com/programa3/ ]
Raphael: curious to see how for we can go. If code can become text, can code generate code again. Perhaps not only code, but also SVG. How graphical can these generated results be?
Clipart generator, after having the progran learn about it from OpenClipArt. A program that learns about shapes and can generate them
raw semantic, mark down
Hans: diverse background. Little bit of programming, little bit statistics.
Use the program as a political activist.
Catherine: get more familiar with the text generator as a writing and reading machine. Take it as a political tool based on a collection of texts. Same interest in the “langue de bois” discourses on Text & Data Mining
Illegaly accessing sources of copyrighted texts for data-mining (there are exceptions for education purposes)
Samuel, graphic designer. Worked on a chat bot, based on DB. Interested about how Neural Networks are done.
interest in markov chains, neural networks,
Andrea : studied graphic design but drifted away from it, interest in language - topical research -- interest on ritualistic aspect of language, experimental poetry, constructed as if was made by a machine. Interest in poetry made as if it would be made by machines, but actually made by humans. Interested in this shifts.
An: part of botopera-team that made dead authors re-enact as chatbots; interest in having 'contemporary' behaviours for Beatrix Botter: http://publicdomainday.constantvzw.org/#1943
***
Two methods/approaches to work with text:
- sintax and language-based, the most easy to get in
- neural networks (most challeging)
***
## Tools
Dada engine, a C program
http://dev.null.org/dadaengine/
Does’t need to get into the code
But you need to compile the package. Look at the README-file: after extracting you need to go into the dada-engine folder and to do 'configure', 'make' and then 'sudo make install' (The sudo is needed to have the permission to create a directory). Probably you get errors and have first to install the following files: bison and flex (with 'sudo apt-get install bison' and 'sudo apt-get install flex'.)
people working with Ubuntu need to install also makeinfo (sudo apt-get install texinfo)
Tests to generate some text (example): dada scripts/manifesto.pb
The NonIsmist Manifesto:
1. language is an illusion.
2. culture is a myth.
The ParaNihilist Manifesto:
1. there is no recovery.
2. reality is a myth.
The NonSurObjectivist Manifesto:
1. class is an illusion.
2. technology is a myth.
Examples:
http://xwray.com/fiftyshades
https://github.com/lisawray/fiftyshades
> open the .pb file
Limitations: make sure that all the possibilities and rules are in there
Recurrent neural networks
http://googleresearch.blogspot.co.uk/2015/07/deepdream-code-example-for-visualizing.html
https://github.com/google/deepdream
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
https://github.com/karpathy/char-rnn
My first pseudo-Shakespeare produced through this RNN: [[Shaky blurb]]
Oops, the model of German political speeches (24,4 Mb of text) needs 463050 x 7s = 37 days to calculate
A first result with only 0,5% of the calculations[[German_blurb]]
Mirco RNN python version
https://gist.githubusercontent.com/karpathy/d4dee566867f8291f086/raw/17d79be172916066982f6ec8886ecf5ba1aa43bd/min-char-rnn.py
If you run it with python 3 like me, here is an adapted version :
https://gist.github.com/raphaelbastide/11ae4bb5e454e5c5239f
An: i'm reading this: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
but I have difficulties understanding some of the schemes - stgh for a break ;-)
A python Patent Generator : http://lav.io/2014/05/transform-any-text-into-a-patent-application/
Dasher, eye-tracking for typing
https://en.wikipedia.org/wiki/Dasher_%28software%29
http://www.inference.phy.cam.ac.uk/dasher/
(Ana & Ricardo are playing with this for probabilistic text generation. See the current progress at [[Dasherpoetry]] )
----- second round (post-lunch)
Ricardo/Ana: We feed dasher with a corpus of Fado, portuguese music lyrics -> [[Dasherpoetry]]
Working on alternative input for the interface to generate text.
Possible corpus to try: fado lyrics; portuguese parliament debates; recipes; code (tried it with kernel.c);
Ann: Installing dada engine
Hans: installed neural network library; now feeding it
Raphael: running minimal RNN python library to generate SVG
- -
22/08 - Cath & Wembo
Dada Mining Engine - txt generator from TDM grey literature (let's try)
http://www.sas.com/gms/redirect.jsp?detail=GMS16435_22380&gclid=CjwKEAjw9dWuBRDFs9mHv-C9_FkSJADo58iMfl_Sl5Pfgi_atBK8lC2scmwTo5Pie4g-e7fx21avhhoCyVvw_wcB
Data mining (the analysis step of the "Knowledge Discovery in Databases" process, or KDD),[1] an interdisciplinary subfield of computer science,[2][3][4] is the computational process of discovering patterns in large data sets ("big data") involving methods at the intersection of artificial intelligence, machine learning, statistics, and database systems.[2] The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use.
teenage (female) language generators:
http://www.smithsonianmag.com/smart-news/teenage-girls-have-been-revolutionizing-language-16th-century-180956216/?no-ist
planes of the euraca dialectizer (in Spanish, thou...):
https://seminarioeuraca.files.wordpress.com/2012/10/planos-del-dialectizador-para-la-construcciocc81n-de-zanjas.pdf
this interesting as an exampe of a (Visual) 3 dimensional space created from 4 letter words in english (begining with a certain letter)....
each point in space is a word and a surface 'wraps' the points (using 'marching cube algorithm - as is used in MRI scans...) to sho clustering of similar words with in the 3D space.
https://www.processing.org/exhibition/works/base26/index_link.html
../images/base26.png
Obama speech generator:
See a message from the president on http://10.9.8.57
Get the data:
A json dump of the database is available at http://10.9.8.57/export
You can download it with the following command
wget 10.9.8.57/export -o export.json
Which will download the data into a file called 'export.json' in your current directory.
It's a list of object / dictionaries with the keys
url => the url of the page from which the speech/transscript was downloaded
text => the origninal text (only the parts spoken by Obama)
cleaned_text => a (roughly) cleaned version where double spaces and annotations like (applause) & (laughter) have been removed
++++Wirelessness! Welcome++++
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
~ ../wirelessness/wirelessness.html <-- tools info ~
~ ~
~ [[wirelessness-tools]] <--- tools info editable ~
~ ~
~ ../wirelessness/ <--- all the stuff ~
~ ~
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Day 2
Debian
OSX + Homebrew
Ubuntu x2 x
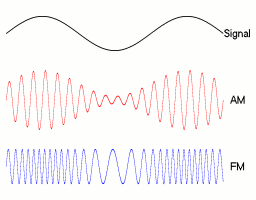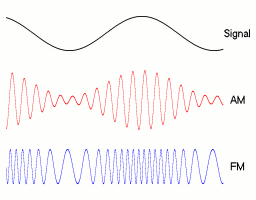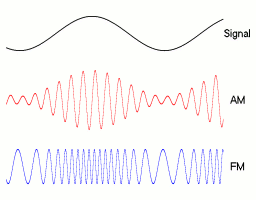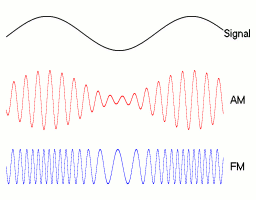
../wirelessness/Amfm3-en-de.gif
Looking at USB key for television (DVBT)
http://gqrx.dk/ GQRX
OSX:
GQRX Binary: http://sourceforge.net/projects/gqrx/files/2.2.0/gqrx-2.2.0.dmg/download
Debian:
sudo apt-get install gqrx-sdr rtl-sdr
you might also need to install pulse audio if you haven't yet!
Windows:
no GQRX look at: http://sdrsharp.com/
Ubuntu :
- direct app paquet manager install :
http://gqrx.dk/download
- french doc install :
http://doc.ubuntu-fr.org/gqrx-sdr
(some trouble here, compiling etc)
Ubuntu already has drivers that recognize RTL devices in their original role as DVBT receivers.
This causes crashes for SDR because the wrong drivers are loaded. So blacklist the DVBT drivers to make sure the RTL-SDR drivers are loaded:
From this error : "FATAL: Failed to open rtlsdr device ubuntu"
Here are commands for the terminal / For ubuntu installation : https://groups.google.com/forum/#!topic/gqrx/4na-dWW3STc
Open a terminal and type:
cd /etc/modprobe.d
sudo nano no-rtl.conf
Add the following lines to the new file:
blacklist dvb_usb_rtl28xxu
blacklist rtl2832
blacklist rtl2830
Save and exit using CTRL+X then reboot the computer.
To confirm you have the drivers (on linux) plug in the device and run:
dmesg
You should get similar output
[114657.303404] usb 3-1.2: new high-speed USB device number 10 using ehci-pci
[114657.409322] usb 3-1.2: New USB device found, idVendor=0ccd, idProduct=00d3
[114657.409330] usb 3-1.2: New USB device strings: Mfr=1, Product=2, SerialNumber=3
[114657.409334] usb 3-1.2: Product: RTL2838UHIDIR <-------------- Look for this
[114657.409338] usb 3-1.2: Manufacturer: Realtek
[114657.409341] usb 3-1.2: SerialNumber: 00000001
Belgium Frequency of interest:
952 MHz GSM towers (encoded digital data)
169.625 MHz Pager system (POCSAG encoded digital data)
Recording and Decoding
GQRX - Record
Audacity - Edit/Cut interesting bits out of audio AND see binary data (effect > amplify > zoom in =))
Multimon-ng - demodulator for different digital encodings
Sox - play and pipe raw files for multimon
Record audio from GQRX, first define an output folder!:
../wirelessness/gqrx-audioout-config1.png
../wirelessness/gqrx-audioout-config2.png
Screenshot from Audacity:
../wirelessness/audacity_audio_POCSAG_encoded.png
Screenshotted audio file, recording of Pager message:
../wirelessness/onesandzeros.wav
Decoding:
https://github.com/EliasOenal/multimon-ng
Linux:
first : http://eliasoenal.com/2012/05/24/multimonng/
comment from
Graham - January 5, 2015 at 2:17 am
sudo apt-get install libpulse-dev
git clone https://github.com/EliasOenal/multimon-ng.git (dependecy = qmake)
cd /path/to/multimon-ng
mkdir build
cd build
qmake ../multimon-ng.pro
make
sudo make install
is it ok ? confirm ? i don't know, you confirm?
ok ubuntu
OSX:
install homebrew
brew install qt
brew install pulseaudio
git clone https://github.com/EliasOenal/multimon-ng.git
mkdir build
cd build
qmake ../multimon-ng.pro
make
sudo make install
If you have multimon-ng ready to roll:
LINUX:
install sox (a commandline sound player)
sudo apt-get install sox
then play your recorded sound file with sox and pipe it into multimon-ng. Make sure you select POCSAG1200 protocol (../wirelessness/POCSAG-protocol.pdf) demodulators
sox -t wav my_recoring.wav -esigned-integer -b16 -r 22050 -t raw - | multimon-ng -a POCSAG512 -a POCSAG1200 -a POCSAG2400 - OSX:
install sox...
(proxychains4) brew install sox
sox -t wav YOURFILE.wav -esigned-integer -b16 -r 22050 -t raw - | multimon-ng -a POCSAG512 -a POCSAG1200 -a POCSAG2400 -
Note: if your audiofile is to noisy, it just doesnt work
test file in : ../wirelessness/
direct link : ../wirelessness/gqrx_20150821_104939_169621000_cut.wav
result : 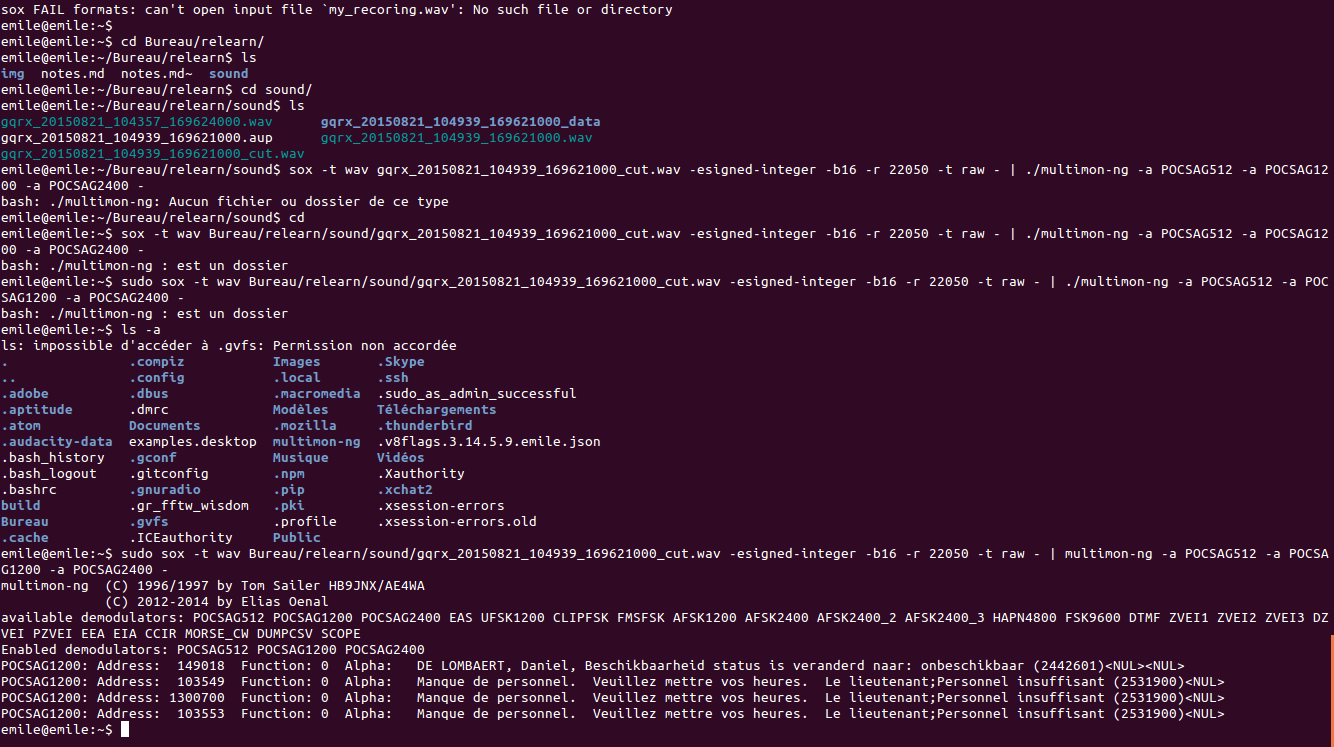
../wirelessness/Capture%20du%202015-08-21%2016:09:06.png
OSX output of ../wirelessness/pocsag_ambulance.wav:
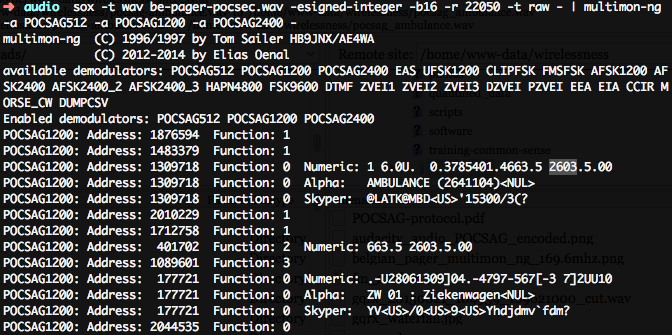
../wirelessness/POCSAG-decoded-output.png
Testfile2:
../wirelessness/pocsag_sample.wav
../wirelessness/pocsag1200_audacity.png
POCSAG1200: Address: 1306201 Function: 0 Numeric: U.5-.6]7[4[U--U.5-.0.-38- 65U.5-4U73491 263U95] 50U95 071301.46939- .69U 5.00000
POCSAG1200: Address: 1306201 Function: 0 Alpha: +++swion+++P=03+++S=C201339.03181 (2923599)<NUL><NUL>
POCSAG1200: Address: 1306201 Function: 0 Skyper: ***rvhnm***O</2***R<B1/0228-/2070<US>'1812488(??
POCSAG1200: Address: 119556 Function: 0 Alpha: Thomas, Joris, Beschikbaarheid status is veranderd naar: onbeschikbaar (2441699
Meaning of the data
'Numeric'
'Alpha' means alphanumeric message, aka ASCII human readble text.
'Skyper'
In belgium the paging network infrastructure: http://www.astrid.be/templates/content.aspx?id=492&LangType=1033
Multimon also works the other way around, so it allows you to SEND pager messages.....maybe the fastest way to reach an ambulance, police, firetruck or a cab ;0
Realtime Decoding using netcat
First tune in to your favorite digital encoded signal in gqrx, then pipe the sound into multimon:
Then define a port to stream the data over in GQRX by choosing a port in the network tab of the audiosettings screen;
../wirelessness/gqrx-audioout-config1.png
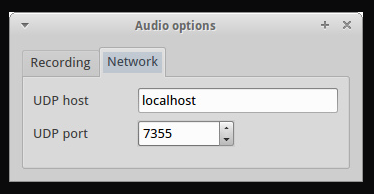
../wirelessness/gqrx-network-settings.png
LINUX
NC, a little test. Open two terminals..
In the first:
nc -l -p 5555
in the second:
echo "test" | nc localhost 5555
sudo nc -u -l -p 7355 | sox -r 48000 -t raw -b 16 -c 1 -e signed-integer /dev/stdin -r 22050 -t raw -b 16 -c 1 -e signed-integer - | multimon-ng -t raw -c -a POCSAG1200 -f alpha /dev/stdin
nc -u -l -p 7355 | sox -r 48000 -t raw -b 16 -c 1 -e signed-integer /dev/stdin -r 22050 -t raw -b 16 -c 1 -e signed-integer - | multimon-ng -t raw -c -a POCSAG512 -a POCSAG1200 -a POCSAG2400 -a SCOPE -f alpha /dev/stdin
OSX
NC, a little test. Open two terminals..
In the first:
nc -l 5555
in the second:
echo "test" | nc localhost 5555
Now for real:
DOESNT WORK, latest OSX compiled version of GQRX is 2.20 and network streaming is only available in 2.3...
Solution:
Use only command line tools:
brew install librtlsdr
LISTEN TO THE RADIO ON OSX
rtl_fm -M wbfm -f 89.1M | play -r 32k -t raw -e signed-integer -b 16 -c 1 -V1 -
LISTEN TO PAGERS
rtl_fm -M wbfm -f 169.650e6 | play -r 32k -t raw -e signed-integer -b 16 -c 1 -V1 -
rtl_fm -f 169.650e6 -g 100 -s 48000 -l 310 - | sox -r 48000 -t raw -b 16 -c 1 -e signed-integer /dev/stdin -r 22050 -t raw -b 16 -c 1 -e signed-integer - | multimon-ng -t raw -c -a POCSAG512 -a POCSAG1200 -a POCSAG2400 -f alpha /dev/stdin
The rtl_fm -f 169.650e6 is the frequency. This doesnt incorporate error margin/offset of your SDR receiver. See below how to callibrate your device and frequency =)
rtl_fm doesnt quit on osx, killall doesnt work, only Force Quiting it via Activity Monitor
Calibrating the RTL-SDR receiver:
https://github.com/steve-m/kalibrate-rtl
OSX:
git-clone ...
cd src
make kal
ERROR ./usrp_source.h:28:10: fatal error: 'rtl-sdr.h' file not found
TODO edit Makefile.am to find the homebrew rtl-sdr.h:
/usr/local/Cellar/librtlsdr/0.5.3/include/rtl-sdr.h
Examples of antennas:
http://www.starantenna.com/
links :
* http://www.satsig.net/pointing/antenna-beamwidth-calculator.htm
* http://www.saveandreplay.com/Antenna_reference_chart.asp
https://rad1o.badge.events.ccc.de/howto:use_hackrf
Width of waterfall is an indicator of the slice size of the spectrum
The internal noise of your laptop needs to be as little as possible: put the antenna away from your laptop
88-110 MHz radio frequencies
Day 1
http://roelroscamabbing.nl/post-www/ <--- where we're coming from
what is radio? why is it relevant?
a kind of media-archeological approach
receive radio via software---floss dev
easy..
merge idea of radio with that of data
1s and 0s
tangible example: wireless diff from radio technopolitically (laws/machines with limitations/political barriers)
wireless car key can be recorded and playedback to open car ;)
topics/questions
radio as an infra---->structure: mapping --there are no general maps
what do you map?
spectrum - influenced by what you recieve --->different ways of mapping
antennas
physical places
materials:
mainly listening
- eventually there are transmitters
- antennas
plan
- challenging crossovers between tools and methodologies
- command line tools that can be piped
- antenna safari in the city--look around, map antennas, diff kinds (very exotic ones, some examples can be found in ../wirelessness/ )
- 1st day: discuss tools, listen to radio
signals in the air which sound like noises thay are actually digital signals, information (so, decoding processes)
- how something in the air can be digital??
radio waves are physical phoenomenons, as light
questions of infrastructures: towers, physical location and materials
looking around town for something that is usually overlooked
reconstruction radio infrastructure
questions of size (antennas...) also signifies their use, their meaning in use
http://www.environnement.brussels/thematiques/ondes-et-antennes/ou-sont-les-antennes/carte-des-antennes-emettrices
keys and live cds with tools already installed
Mapping Wifi through long-exposure photography: http://www.nearfield.org/2011/02/wifi-light-painting
Sniffing public WIFI data/urls from passing trains: http://trainwatch.u0d.de/
Legality of listening (IN belgium, only to legal to listen to certain frequencies / services, others are illegal... for privacy reasons)
/ an inventory of experiences
/ an inventory of absences
/ a collective glossary
/ an inventory of questions
/ an inventory of tensions
body-tools-interface-social network
*change the interface: e.g. parody of what data actually means (you are lazy, you are fat)
*deconstruct rethoric/ideology of software/product: e.g make human below->look at and modify software rather than model
*get different data with same kind of device:e.g. either experiences/states normally escluded or apply to something not human at all (how can we use fitbit for something else?tracking the shaking and moving around of keys in relearn/a device/a car)
* combining the data of many, rather than visualising the data of one
*using data to create an ecosystem (collective tamagochi)
* swapping data between participants - no longer a static record, but instead a 'challenge' to be undertaken e.g. to drink the same amount as someone else, or to remain as 'sedantary'
*use the same tricks as they do be partly measuring and quantifiying and partly uploading personal information but instead of filing the number of glass of water you can introduce some context history sense of place and time.
* narratives of the self to accompany the 'data' that is determined by the device/ platform super interesting but how to represent this very tricky
*invert the process: get measurments from social, on own interface and have to apply it to life (need to walk and drink as a random person/obsessive did today)
*use the patter recognition (from text gen group) on vector files used in interfaces, to map recurring visual elements- attempt to map the discourse through its visual "rethoric"
linked work strands
- alternative data sets - personal, contextual, social, or other - that include other paramters. this can be automatically collected using a device (eg smartphone) or manually entered (as is the case with fitbit)
- an alternative method of visualising the data - a differnet field other than the 'car dashboard' that is usually presented - using meshes from reMakehuman????
- use the device to generate 'false' readings using alternatives gestures, movements, performances...-->e.g. electronic monitoring ankle bracelet hack mechanical fitbit hack put it on your dog, on a rotating drill how to simulate the data that they want. artist collective proposes diverse tricks and hacks http://www.unfitbits.com/
../images/dashboard.png
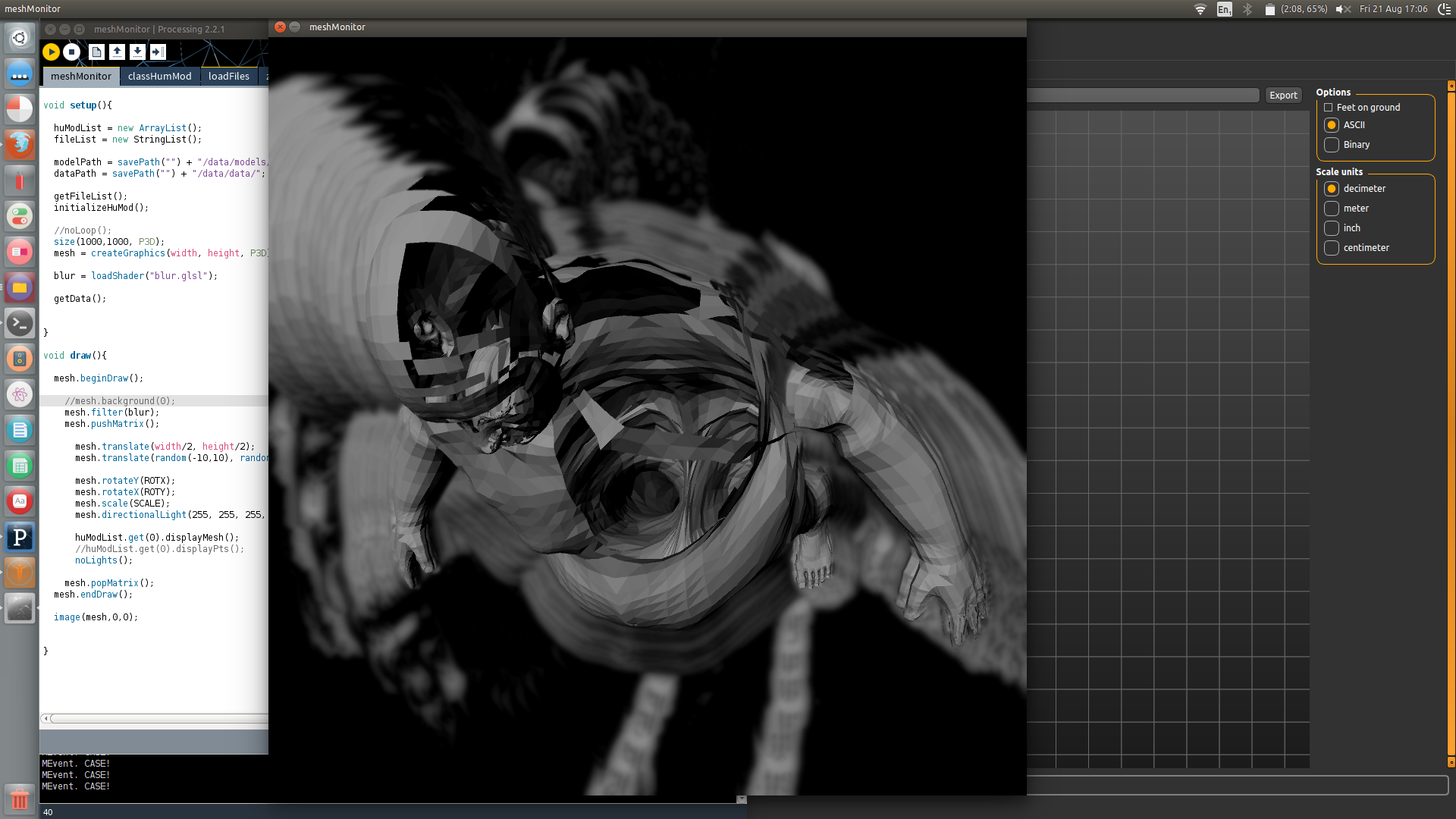
../images/meshMonitor.png
Possible outcomes:
tutorial videos
alternative quantified self device as a protoptype or as documentation video
live fed characters
versioned characters eg: with a sense of evolution
...
coming from the experience of the (cyber)feminist software meetings samedies--learning python ourselves
...
how many glasses you drink, how many steps you make..
the role of commercial device in it.. fitbit .
entering of a discrete measuring probe in a process that was intimate.
clash
start up getting big in the stock market
many insurance companies give a fitbit to their client collect the data and give back incentive
---
instead, a global, holistic point of view.
the idea of self-awareness, in its thousand years tradition.
a contrast with the western current self-quantification
A long history of relation to walking as a nurturing process a thinking tool from aristotle"walking is for the sake of bowel movements"walking principles or see henry david Thoreau Walking
Hearing a heartbeat becomes an obsession biological sounds are really intrusive they create a coccon
Measuring walk you need to reach the treshold at any price.
infinite kowliflower
(solution to world hunger!)( need to re-write the minestrone script)
Mandlebrot!
fractal is some type of quantification.. what is the nature of this quantification?
live feedback with information...
problems:
* how to get the fitbit data live
is completely encrypted in its communications, and the data gets uploaded to a server and then gets back as 'fitbit' data, with the visualization.
The data is categorized in the way demanded by fitbit social network
pedometer (steps counter) -- measures periods of rest
http://www.walker.domainepublic.net/ previous project that features a pedometer we can use it to get a more dense data.
Fitbit categories are:
Corps
date IMC fatmater
Food
Weight Calories
Activities
Date Calories brûlées Pas Distance Étages Minutes Sédentaire Minutes Peu actif Minutes Assez actif Minutes Très actif Dépense calorique
Sommeil
Date Minutes de sommeil Minutes d'éveil Nombre de réveils Temps passé au lit
Ben allard has hacked the fitbit and other jawbone ref galileo project on bitbucket
https://bitbucket.org/benallard/galileo
Anita tells the story of a previous job where she was doing post delivery and was given gps trackers where she modified the sheets tracking her path before giving them to her boss
Idea of making a new smart watch that would collect other things the joy of your walk the discoveries the encounters.
In the spirit of previous videos make a tutorial of what could be an alternative quantified self device.
a provisional idea: fitbit like a tamagotchi...but hey, it exists already! http://www.engadget.com/2014/04/30/leapfrog-leapband/
Question can fitbit see if you enter in collision with another human being?
If we were to make a new interface that would be more context based could we use the same tricks as they do be partly measuring and quantifiying and partly uploading personal information but instead of filing the number of glass of water you can introduce some context history sense of place and time.
A: feeling good= being unaware of one's body
like with infrastructure,tools etc, i become aware of my body when it breaks, when it misbehaves
* How fitbit works is a way to think about the economic structure built into it (how encryption protects it's economy)
* Once you have several 1000 collections of data it changes it's value
* The fact that data is stored remotely "mediated self-awareness"
* Questions of how the human is visualized
the visualization question
makehuman is a free piece of "parametric" software for making 3D models of people for games
mmmm sliders
...far off the ethnicity scale
gender, age, muscle, weight, height, proportions, aftrican ?!, asian, caucasian
changes to the source code changed the narrative in the software.. eg. ethnicity slider --> RGB sliders
file links viz showing how the python code is interlinked (over 200 python files)
using procesing to make visualisations
/ an inventory of experiences
/ an inventory of absences
/ a collective glossary
/ an inventory of questions
/ an inventory of tensions
reMakeHuman
https://github.com/phiLangley/reMakehuman
reMakeHuman is a hack/ destablisiation fork of the 3D character modelling software 'makehuman'
http://www.makehuman.org/
the original software is a tool for early stage modelling of digital characters for games/ animation/ movies. the software presents itself as a parametric mdoelling system, in which the user can modify variables to create a range of outcomes. however, the parameters that are used to deifnce the 'human' are, at best, questionable....
- gender
- age
- height
- weight
- muscle
- african
- asian
- caucasion
this limited set of 'high level' parameter is accessed by the user through a series of 'sliders' - a typical GUI feature. however, when we look closer at the source code, the story is a little different.....
the reMakeHuman project is a an attempt to create a viable alternative character modelling platform capable of creating other 'humans' through questiioning
- the underlying paramettric relationality
- other types of variable that could be used to create a more 'personalised', rather than generalised, piece of software
- the nature of user interface that 'justworks' versus somethign tha is more unstable and unpredictable#
there are many ways to edit the make human software....the source code contains image files, 3D models files, text file as well as python code. modifications to each of these source files changes the software in some way
- changing the software, rather than changing the model......
../images/distortions_5.png
../images/fileExplorer.png
proposal:
urban reconnaissance
methodological approach to the city.
interested in urban exploration from wide perspectives...
http://exercises.oginoknauss.org/
built aspect
discursive aspect
political aspect.
64 definitions of city from 64 aspects
focus on the narrated/represented city
how the physical city builds a parallel realliy of stories/images/films
how to map the cinematic city
Using pandora (http://pan.do/ra )
locally: http://10.9.8.254/
'good luck using films of brussels to represent brussels'
also possible to look into representations of brussels in the forms of sounds
---
[oginoknauss]
background in occupied social center in florence
cinema projects interacting with the defence of the space ( still in tension with the old communists.. )
fertile moment in italy, cross pollination between struggle, underground, arts..
alternative geographies of florence
atlas of the alternative city
--- 'methodological toolbox' aknowledging the fact that you can't reduce the city to one specific aspect interesting similarity with the recent reroam discussion on 'pseudo-categories'... need an angle to give depth to the look, without pretending it's exhaustive.. aspects overlap all the time. -- redividing the categories: formation transformation appropriation representation -- 'productive city' in naples, traces of artisanal activities in the names of the streets.. the productive part seems to be as cultural production.. -- interesting ways cinema relates to city.. crossing between cities that happens through cinema.. ie. movies set in net york are shot in berlin cos its cheaper.. c'est arrive pres de chez vous.. the belgian hybrid.. or the city as built in the cinema, tativille for playtime... -- cinematic mode of production. jonathan bellar. 2006. "cinematic modes of production are deteritorrialized factories, in which we perform value producing labour." internet as value producing traffic. ha -- so what does it mean to map the cinematic city? is it mapping brussels with this methodology? or actually using brussels to understand the different relations between cinema and city? brussels as a way to enlighten the cinema-city relation... and the cinema-city typologies to delve into brussels..? how a methodology can be developed via a concept, while a concept is researched via the methodology.. -- Another element: The screens in the city... moving image invasive and becoming urbanism.. JCDecaux is shaping the city more than any architect.. JCDecaux through infrastructure, images, etc.. one company incredibly put in a position of power (via european union..) how is this made evident by infrastructure - hubs/nodes and flows? (train stations, bike rental) -- making a difference between cinematography and still image production Roland Barthes amorous distance - from the architecture of the cinema into the cityscape Try to look for specific relations which can express the complexity of these relations rather than one section The interest may be not one black room or screen culture, but the movement from moving image to real movement through the city to moving image - hypothesis : there is no amorous distance anymore, we are embedded in a network of moving images. What is in between the image and the gaze? -- http://bureauxdetudes.org *** DAY 2 Building the city walk for Sunday (( 1) )) *WE ARE HERE. (( 2) ))========||======== ((| ||3) \ ))| || 7) \ ((| || \ ))| 4)||================== ((| || 6) \ 8) ))| 5)|| .-' ((`. || 9).-' )) `. || .-' (( `. ||.-' )) `.|| 1)* Horta Hotel Aubecq http://www.aubecq.be/ http://hotel-aubecq.be/remontage.html http://wiki.blender.org/index.php/Community:Science/Architecture/DigitalSurveying/HotelAubecq [[aubecq]] 2)* WTC Tower Exercises: city of flows (flows of consumers meet flows of traffic) 3) * Cinema ABC Adoplphe Maxlaan 149, 1000 Bruxelles 4) *JCDecaux screens in the city.. villó, metró.. infró Location: Brouckere, Anspachlaan Exercises: the city of screens 5) * Le Palace cinema Bouvelard Anspach 85, 1000 Bruxelles * UGC Brouckere Exercises: transforming city 6) * cinema nova 7) * Congrés building *RAC GEBOUW transformed in a screen with very low framerate.. by polish artist Gomulicki 8) * Parlamentarium as a represantion and staging of power and the city Excercises: governing city / power city _I Love EU https://www.youtube.com/watch?v=g3d2qTCM98c 9) Marolles (Palais de Justice) PleinOpenAir - Le Chantier des gosses https://www.youtube.com/watch?v=UNzaNHqycjM https://www.youtube.com/watch?v=sY6LtAww8Po - Cité Modelle - Haren, building site of the maxi prison. *the eternal problem of the map.. __ finding subjective forms of mapping - subjective situations in order to deviate from the "objective map" seeing THE MAP not as a start and and end of any discourse on the city, but actually as one of its site of tension. what about an ethermap? http://mike.kruckenberg.com/archives/2006/05/google_maps_in.html
http://pad.constantvzw.org/p/trinary
[[trinary]]
Text generation
http://pad.constantvzw.org/p/text_generation
you can work on different levels:
* easy grammar algorithms
* recurrent neural networks, can be applied to text http://googleresearch.blogspot.be/2015/06/inceptionism-going-deeper-into-neural.html
learn to talk: http://karpathy.github.io/2015/05/21/rnn-effectiveness/
* take existing code and see how we can use them
ex : http://botpoet.com/
Possible interests:
- legal language = ritualistic / how to engage with it in machinic way
- write your own Shakespeare, experiment with types like in some literature
- automated twitter commenting in certain style (f.ex. antipatternalist comments to sexists)
- look at what computer does with language precisely
- reverse the spam
tools : pattern
possible to combine with text mining
algolit : experiment using markov chains (in an analog way, using dice)
<<<
fifty shades in C, automatic erotic texts
recursive neural networks
incremental means of traning neural networks to produce texts from totally random to increasingly well formed text.
the code validates how much text is text-like... how much it is shakespear-like.. so its
supervised vs. unsupervised learning
neural networks are actually quite old (Perceptron 1960's)
Markov chains, example of generative calvin & hobbes. (Calvin and Markov)
http://www.joshmillard.com/markov/calvin/
Using large-scale brain simulations for machine learning and A.I.
http://googleblog.blogspot.be/2012/06/using-large-scale-brain-simulations-for.html
https://static.googleusercontent.com/media/research.google.com/en//archive/unsupervised_icml2012.pdf
**********************************************
presentation (20th August)
notes/
- the ritualistic reality of language situations
- look at different text generators and to what they do
- - many times the language is so realistic (human) that is difficoult to see a difference (perhaps through the abuse of stereotypes)
- e.g.
- - a google algorithm that finds in a text also what is not there (different informations that are not direclty expressed) or (the algorithm learns how to speak in the stile of shakespeare - considering spaces in between words)
- - a computer learning to play a computer game (Marl/O - Machine learning from videogames - youtube)
uses:
a kind of 'commedia dell'arte': tipes of bots playing a commedia on twitter...
play with administration on a computer generator, playing with the regularity of the language
the tools are the starting point, you are not asked to know how to code! play around and explore these tools in different ways
- but the code is the 'grammar', you need to look at how these things are constructed!
- looking for the political implications of administrative-institutional language, ways to hack them
- looking vs reading - understanding parodies
- connection with data mining topic of the Training Common Sense track, related to text mining
Continues in http://10.9.8.7:9001/p/text_gen
truth is just language
to say something is true is to pretend it is adequate for any purpose.
it's a crazy notion.
it's 2000 years we are after this crazy notion.
how can we exit this crazyness?
the notion of truth has pervaded everything.
we need to understand how it came that it took all that space
in a place called Uruk, the first 'real'(real!=true) city as we know it, first militarized society, arithmetics starts. abstraction starts.
then you can talk about people. an abstraction. the stage of abstraction now is computers.
training common sense
* shift -->
- before, traditionally : thinking in categories, researching for the truth through questionaires with predefined categories
- now, big data : thinking in raw data, natural 'truths', the truth is out there (in the raw data) just undiscovered
- * but... categorisation is still present in data-mining, but more hidden, and therefor harder grasp
- * still there are categories, but they are often disguished as math
* co-intelligence between humans and machines
* there is a lot of un-rawness to this data
* repeat the model untill the model is true
- example: history of western classical music doesn't involve woman, a comment was: but i looked, there are no
- example: alternative scientific truth searching methods --> work on (non) common sense valid truths
* [how]? [you]? [write]?
http://10.9.8.7/images/gender-female-most-common-words_natural-result.png
from: the article Toward personality insights from language exploration in social media
door ut te betalenhttp://10.9.8.7/images/article7.png
machine categorisation of positive / negative words
http://www.wwbp.org/data.html#refinement , from the article: Personality, gender, and age in the language of social media: The Open-Vocabulary Approach
looking at applications
Facebook messages Gender/Age profiles
Hedonometer --> http://hedonometer.org/
going to Knowledge Discovery in Data steps, by looking at Pattern
step 1 --> data collection
step 2 --> data preparation
step 3 --> data mining
step 4 --> interpretation
step 5 --> determine actions
Pattern
created at CLiPS, a research project at the University of Antwerp
http://www.clips.ua.ac.be/pages/pattern
annotating the presentation/
dealing with large amounts of data and triyng making senso of that
big data: the idea of looking at knowledge through categories
but its also raw data, which machine can 'read' through without thinking in relation to these categories (looking for truth)
the crudeness of the presented results: what does that mean? (gender differences in social medias)
what does it mean?
we wanto to look at:
- data collection (thier technological as well as social context)
- data preparation (look at the rough raw data and its next 'use')
- data mining (looking into mathematical models, graphs; the translation from linguistic models to mathematical clusters; looking at different projections, what are the differencies? the 'suitability' of the models in relation to the outcomes)
-
-
what we want to do:
- look in actual text mining programs, look and discuss what happens
- look at documentation on the collection/ing of this datas (exuses, apologies about the political/social problematics expressed in the 'truthfullness' of the mathematical results) - revealing subtleties
- the research on the data mining is very close to the text generation project
example:smilies-->not recognized as meaningful
meaningfulness of cleaning data (we know it is-like cleaning toilets- but we don't do it)
use facebook data to train next mining process - 'self-fulfilling prophecy' of common sense
data-mining->"the" step, but actually just a small part of the process
mathematical model--->truth finding moment-->the machine performance
with enough time, with enough data...
compare first results with standard, most of the time human-produced data
e.g. libraries of positivity/negativity online
The best material model of a cat is another, or preferably the same, cat.
Philosophy of Science 1945. (Wiener)
Project IMB: you are what your write on Twitter: http://venturebeat.com/2013/10/08/ibm-researcher-can-decipher-your-personality-in-200-tweets/
Suggested references
An article that poses questions and reflections on methodology applied in research. They obtain "valid cientific" results that have no common sense at all. The abstract is quite inspiring
http://www0.cs.ucl.ac.uk/staff/m.slater/Papers/colourful.pdf
training-common-sense day 2
http://10.9.8.7:9001/p/quotes : "on the circularity of classification"
- "Gandy theorises that the attentions given to classification, in its naming as relevant/not relevant,
- criminal/innocent, and so on, are determined by the problems assigned to each instance of its enquiry.
- In other words, types are assigned to associated preemptive actions based on the desired outcomes.
- The assignment of relevancy can then be seen as assigning relations of power, and the ownerships of
- this power reside in the ability to name a particular instance within certain contexts that require
- attention" <ref>Becker, K. (2009) The Power of Classification: Culture, Context, Command, Control, Communications, Computing. in Becker, K. and Stalder, F. (eds.) (2009) Deep Search: The Politics of Search Beyond Google. Innsbruck: Studienverlag Gesmbh</ref>
- ...
- What emerges is the quantification of life and social relations that carry potentials to produce other powers and biases within the same spaces that hold great benefit for our social environments. Within this framework classifications are the grounds on which both imbalances and social advances are created and articulated.
ways to go
- going through Pattern, following the KDD steps
- re-do (try to) of the facebook-messages data-mining
- look at types of visualisation
- - wordclouds
- - words have multiple meanings
- - graph module in Pattern
- two ways of speaking about a KDD-proces
- - the data speaks / i didn't make this up
- - computer vision
* [excuse me video] --> contradiction of desired + undesired result
* which is also present in all the KDD steps --> common sense
* interesting --> laughter --> when do we laugh?
* so many layers of signification that were present to create such wordcloud ...
- - facebook user which is female = (is equalized with) "shopping, boyfriend, etc."
- - the wordcloud is a kind of basic vocabulary, disregarding the more complex ways of expressing an urge to shop (for example)
* difference between a truth, or a cultural pattern that appears in the language in a certain situation
* we know there are patterns in language use, we notice them ... science tries to create models to do predictions ... but what would be the solution to these patterns ...
* if we would create such a wordclouds on for example race-classification ... it could be a more rigorous result ... but yes, it's the data right?
* will there always be a bias result of gender-classification? even if you perform an adequate research process
* difference between:
- - black people are criminal
- - there are more black people in jail
* there are analysis on age, gender, health, personality, ... --> global topics that can be connected
* statistics is a tool that is the result of an abstraction
- - a main tool of science since the 17th century
* philosopher bigologist and ethologist (comparative animal behavior science) (died in 1978) ....Konrad Lorenz : "you have to swim in observations, before you can start a statistical experiments"
- - perception of shapes/forms
- - you have to understand the size of the system, before you can start
* history of orientic parole (the choise if a prisoner could go on parole), descision making process of this is highly influenced by data-mining prediction-tools
* there are suggestive algorithms for dating/products/etc., one loses your ability to make a descicion
- > example: GPS --> makes you lose your ability to navigate
- < but humans and machines are maybe not naturally exclusive... the presence of GPS might change me, but what is the balance between relying on machines --- trans-intelligence
* how did the facebook users react on the results of gender-mining? Look at qualitive elements of the research
* what is the aim, interest of facebook to focus on gender-mining?
going through Pattern, following the KDD steps:
- download Pattern, options:
- examples:
----------------------------------------------
amazing polarity average
amazing appears two times in the en.sentiment.xml-file:
- 1. <word form="amazing"
- wordnet_id="a-01282510"
- pos="JJ"
- sense="inspiring awe or admiration or wonder"
- polarity="0.8"
- subjectivity="1.0"
- intensity="1.0"
- confidence="0.9"
- />
- 2. <word form="amazing"
- wordnet_id="a-02359789"
- pos="JJ"
- sense="surprising greatly"
- polarity="0.4"
- subjectivity="0.8"
- intensity="1.0"
- confidence="0.9"
- />
In the example that Pattern provides (pattern-2.6/examples/03-en/07-sentiment.py) the word amazing gives a result of a polarity of 0.66666:
- from pattern.en import sentiment, polarity, subjectivity, positive
- for word in ("amazing"):
- print word, sentiment(word)
- >>> amazing (0.6000000000000001, 0.9)
which is the mathematical average between the polarity value of 0.8 of the first sense of amazing, and the polarity value of 0.4 of the second sense of amazing.
meaning is mathematically averaged...... (???????)
Looking through sentiment examples:
# It contains adjectives that occur frequently in customer reviews
ie sentiments related to consuming, but consuming what
en-sentiment.xml
"The reliability specifies if an adjective was hand-tagged (1.0) or inferred (0.7)."
Inferred = decided by the algorithm? Sentiment according to the machine?
- <word form="frustratingly" wordnet_id="" pos="RB" sense="" polarity="-0.2" subjectivity="0.2" intensity="1.2" reliability="0.9"/>
it appears there is only reliability of 0.9 to be found; not each term has a reliability score.
Some adjectives have no wordnet id. Is the file a mash-up?
Sometimes the term "confidence" is used (reliability and confidence are never found on the same word, and confidence is either rated 0.8 or 0.9). Could this be the same?
Comparing en-sentiment.xml to SentiWordNet 3.0
02022167 0 0.25 wealthy#1 moneyed#2 loaded#4 flush#2 affluent#1 having an abundant supply of money or possessions of value; "an affluent banker"; "a speculator flush with cash"; "not merely rich but loaded"; "moneyed aristocrats"; "wealthy corporations"
00076921 0 0 afloat#2 borne on the water; floating
From sentiwordnet annotation:
"objectivity = 1 - (PosScore + NegScore)"
affluent: objectivity = 1 - (0 + 0,25) = 0.75
afloat: objectivity = 1 - (0 + 0) = 1
http://sentiwordnet.isti.cnr.it/
----------------------------------------------
Presentation Hans Lammerant
http://10.9.8.7:9001/p/training-common-sense -> context
rewritten version by FJ --> http://10.9.8.7/training-common-sense/Hans_presentation1.html
----------------------------------------------------------------
----------------------------------------------------------------
construction of a certain visibility
text get simplified, a construction
get data out of text, to make it 'treatable' with math
step 3A: turning text into numbers
example --> source: french and english versions of Shakespeare. Bag of words: each word is placed in a mathematical space.
bag-of-words:
- first step = text --> drop all meaning, drop all connection between words, what you get is a word-order
- this is reading a text in a very specific way, it is the way how the computer reads it --> it is counting the words
- what you get --> is a vector in a mathematical space
- "my algorithm is reading Shakespear like this right now"
- "there are 26 dimensions, mathematically that is no problem"
Each word an axe in a multidimensional space
Now: bag-of-letters, 'only' 26 axis; ie 'only' 26 dimensions; the vector has 26 coordinates
It is hard to imagine ... if it would be a, b, c you would have a 3D space
22 points (ie texts) with 26 dimensions: how many e's, how many b's
each text has only one point in the 26 dimensions
every text is a point in this multi-dimensional space, having 26 coordinates for the 26 dimension
"why does it have to be dimensions (why do we use the term dimensions)?" --> why this metaphorical form?
if you reduce dimensions, it gets simpler, you lose info
n-dimensions -- a math idea, not related to our 3D space
one of the basic tools in mathematics is thinking in dimensions
we do not talk about physical dimensions, we talk about mathematical dimensions
datamining: 'trying to get some meaning out of this'
now: translating the texts to a mathematical space. For this you need to simplify: forget about word order (if you would keep it, it would explode the amount of dimensions)
the points are a very simplificated model of the text, which got rid of the meaning . It is common practice.
an ordered, or unordered text of Hamlet, does not matter for the machine
your label/annotation is another column/dimensions/coordinate in your dataset, that changes the location of a point within the 26 (now 27) dimensions
> what does the algorithm see?
Multidimensional scaling
reveals clusters, in this case: language difference.
(example: from a lot of colors in a picture to grayschale, and so to two dimensions)
you rotate the axis in different way until you see the biggest difference.
Metric MDS = multi-dimensional-scaling
--> the act of rotating the axis, in order to find an axe on which you can make a better differentation between points
MDS = a program, a mathematical tool, which helps you finding the highest contrast
this step help you to find a view, and a way to reduce dimensions, and you can throw the rest out
two-dimensions --> is a plane
three dimensions --> projecting points on a plain
this is also possible with 26 dimensions
and you look for a plane which covers your points ...
in order to decide the point of one text into the 2-dimensional graph, in this example all the coordinates of the 26 letters are summed up, and divided by 26 --> average number
these number doesn't have any meaning anymore, it is a way to differentiate between texts
making a bag-of-letter model is a very simplified model of the texts, on such a level that you can read another type of information
this step reduces information, not by reducing dimensions
(if you're looking for a model ... you start to make a dataset, with an amount of dimensions... but in order to get a working model ... you need to be able to recognize your expectations ...)
modeling the line
from now on, you can throw all the data-points away, because you have a model
this is the moment of truth construction
"and you hope that it has something to do with the reality you want to apply it to"
"the big leap is to check if your model is able to predict something later"
knowledge discovery implies it can find clusters by itself
what if you find a contrast in a vector space, but you don't know what it means
> how do you know what it means?
< the only way is to check it to other data
> so you check each regularity, even if you don't know what kind of respondence with reality it has
< a kind of myth what is present in data-mining, is that an algorithm can discover this respondence
the question is if the X's & O's come before the line? or after the line? when is the data labeled? is that a process?
(is the data supervised?)
a kind of flip-flop process where you look for a differentation, then there is a moment where you can create your model, and then your differentation is *fixed* and from that on, it applies the model to other data
a hypothesis is always present in creating a model
in traditional statistics, there always is a hypothesis to get what you want
in data-mining, there seem to still be a hypothesis present
the point is: when do you formulate your hypothesis?
- now: when you see a differentiation, you start thinking what it could mean
- so, there is another moment of formulating your hypothesis
validation phase
--> a validation method is comparing your results with another text
overfitting --> making sure if very specific points are included in your model ...
there are standard validation procedures to reaching the moment of 'it works'
- for example the 20% test-data, and 80% building data
- --> the 20% need to be labeled on before hand, in order to check the model's results
Q: What is the name of the dimension to rotate around?
A: The rotating has nothing to do with meaning ... it is just the possibility to represent in 2D at some point?
A: The average is one point in the process. Relative distribution of letters ... we normalize. Afterwards: algorithm helps you find the plane with the most extreme difference.
Q: Can you see the process without, before the normalization
A: If I would not normalize, ..
Q is there a way of looking at the process of the algorithm? to look at the moment between
- - there are points in the space, and the algorithm looks at it
- - and the algorithm gives back a result that a human can read
outliers
> your algorithm gets better if you take your outliers out
< is the outlier a spelling mistake? or really a outlier?
> is removing outlier a standard practise?
< well, checking it is. and checking if it is a mistake or not
> does the amount of dimensions influence the efficiency of the model, is there an interest in the amount of dimensions?
< if there is a difference between 1000 and 1000000, there is a difference ... and there is also a difference in type of dimensions ...
> i'm trying to understand the economy of the dimensions...
>> but the economy is in the results of the model?
Random notes from Sunday
Seda preparing a session on Machine Learning: http://pad.constantvzw.org/public_pad/touchingCorrelations
Weka: http://www.cs.waikato.ac.nz/~ml/index.html (floss java package for machine learning)
"2 features are redundant if they are highly correlated with each other"
"occam's razor: simpler models are usually better"
Hamid Ekbia, Bonnie Nardi, Heteromation and its (dis)contents: The invisible division of labor between humans and machines
http://firstmonday.org/ojs/index.php/fm/article/view/5331
Alison Adams, Artificial Knowing: Gender and the Thinking Machine (1993)
where to go today (& tomorrow)
* What would be a sentence that would have a sentiment polarity of 0.0?
popular polarity analysis
- - sentiment analysis --> only polarity in Pattern that has examples
- - IMdB movie database, star ratings
- - amazon-turk procedure (World Well Being Project?)
- - manually rated dataset (Pattern)
- - age
- - gender
- - personality
* A proposed exercise:
we can change the en.sentiment.xml file in Pattern, with our own adjectives. --> which adjectives?
file used in other programs, elements of pattern?
- list of exercises that could be done
* A map of Pattern structure
and adding notes
looking at geneology; a mapping of where things come from or where else they appear
* Introduction: pattern-readme-plus.md
introduction to the forked Pattern-2.6
* A note added to ...
how to name our comments/notes
- - weird feelings about the fr.sentiment.xml - add a 'note'
- -
- -
* An explanation of vector-projections --> examples
* Some quotes, references to critical resources
* a reflection on the data-mining culture --> where?
an option is ....
- our-critical-fork-folder ....
- - pattern-2.6.zip
- - weka-3.0 (?)
- - data-mining-culture
or ....
- meta-mining
- - pattern-2.6-critical-fork.zip
- - weka-3.0-critical-fork.zip
- - data-mining-culture
- - ...
- - ...
* how to create a 'critical-fork-method'
- - Magic comments
- - Issues
- - add FIX-IT-like files, following this standard -> ask Michael
- AUTOPSY
- DISSECTION
- DISCUSS
- DEBATE
- DEBATABLE
- STUDY
- REFLECTION
- #CRITICAL-ISSUE
- Performance
- Read-write-execute
training common sense - day 3
adjectives
http://10.9.8.7/training-common-sense/sources/pictures/good-bad.png
from: Using WordNet to Measure Semantic Orientations of Adjectives --> http://www.lrec-conf.org/proceedings/lrec2004/pdf/734.pdf
http://10.9.8.7/training-common-sense/sources/pictures/sentiWordNet.png
http://sentiwordnet.isti.cnr.it/
adjectives in WordNet
references
Using WordNet to Measure Semantic Orientations of Adjectives --> http://www.lrec-conf.org/proceedings/lrec2004/pdf/734.pdf
book about WordNet --> http://10.9.8.7/training-common-sense/sources/texts/wordnet-an-electronic-lexical-database-language-speech-and-communication.9780262061971.33119.pdf
history of WordNet
George A. Miller is initiator of WordNet,
from two different fields, he worked on a computational lexicon:
- * AI
- - George A. Miller + Philip N. Johnson-Laird
- - componential lexicon
- --> looking for significant atoms
- - ±1976 - 1985
- * Cognitive Studies, Psychology
- - relational lexicon
- --> IS-A-KIND-OF relations
- - ±1985 and onwards
- WordNet developed at Princeton University, at Cognitive Studies
work @ WordNet on adjectives
- - Philip N. Johnson-Laird
- 266 pairs of antonymous adjectives ------------> 25 classes of nouns
- - Christiane Fellbaum
- 266 pairs of antonymous adjectives ------------> 25 classes of verbs
- - Kitty Miller
Philip N. Johnson-Laird
(born 12 October 1936) is a professor at Princeton University's Department of Psychology and author of several notable books on human cognition and the psychology of reasoning.
— from: https://en.wikipedia.org/wiki/Philip_Johnson-Laird
profile: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3250179/
portrait: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3250179/bin/pnas.1117174108unfig01.gif
When complex technology starts spiraling out of hand, this abundance of information hinders our ability to make reliable decisions.
“Eventually,” Johnson-Laird says, “the computational demands overwhelm them, and this often culminates in catastrophes.”
— from: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3250179/
worked on the grouping of adjectives to classes of nouns.
Can we find this file?
adjectives in Pattern
references
"Vreselijk mooi!" (terribly beautiful): A Subjectivity Lexicon for Dutch Adjectives --> http://www.clips.ua.ac.be/sites/default/files/desmedt-subjectivity.pdf
- 1. Introduction
- - "Textual information can be broadly categorized into two types: objective facts and subjective opinions (Liu, 2010)." --> first sentence of the article
- - two approaches for Sentiment Analysis:
- - using subjectivity lexicons (Taboada et al., 2011)
- - using machine learning text classification (Pang et al., 2002)
commodification of difference
Looking at 'the cyclic commodification of difference', and entry points for a critique of text-mining (thank you Seda Guerses)
Alison Adam, Gay men, Gaydar and the commodification of difference (2008)
Alison Adam, A Feminist Critique of Artificial Intelligence http://ejw.sagepub.com/content/2/3/355.refs (1995)
to compute the semantic similarity/relateness/mathematical-relation between words
departing from the article "Vreselijk mooi!" --> http://www.clips.ua.ac.be/sites/default/files/desmedt-subjectivity.pdf
- - 1.100 adjectives manually annotated on polarity and subjectivity
- - then, they want to extend that set to 5.000 adjectives
- 3.1. Using Distributional Extraction
- There is a wellknown approach in computational linguistics in which semantic relatedness between words is extracted from distributional information (see e.g. Van de Cruys 2010 for an example for Dutch). The method uses a vector space model with adjectives as vectors (i.e., matrix rows) and nouns as vector features (i.e., matrix columns). The value for each vector feature represents the frequency an adjective precedes a noun. It is then possible to take the cosine of the angle between two vectors as a measure of similarity (cosine similarity). In other words, adjectives followed by the same nouns are more semantically related than adjectives followed by different
adjectives nouns. The method then uses dimensionality reduction and clustering by cosine distance to create groups of semantically related words.
then, we looked at: Van de Cruys 2010, called Mining for Meaning, chapter 2 (page 31) --> https://www.rug.nl/research/portal/files/14692283/14complete.pdf
matrix of adjectives
a1 [ n1 n2 . . . . . . ny]
a2 [ n1 n2 . . . . . . ny]
a3 [ n1 n2 . . . . . . ny]
a4 [ n1 n2 . . . . . . ny]
a5 [ n1 n2 . . . . . . ny]
a6 [ n1 n2 . . . . . . ny]
ax [ n1 n2 . . . . . . ny]
example: micro/minimal context of adjectives
- - Looking at the relation between adjectives and nouns, is a way to have a sense of the context that a word appears in.
- - What nouns could adjectives modify?
- - you can calculate the relation between a certain adjective to a certain noun (a1-n1)
a1 n1 --> amazing book occur 5 times together
a2 n1 --> awesome book occur 10 times together
a3 n1 --> beautiful book occur 15 times together
a1 n1 --> amazing book
a2 n2 --> awesome person
a3 n3 --> beautiful flower
- --> these nouns fall under the same class of nouns
bright, brilliant, apocalyptic ... future
brilliant, well-written, interesting ... book
mathematical 'relation' or 'similarity' vs. semantic 'relation' or 'similarity'
http://10.9.8.7/training-common-sense/sources/pictures/similarity-of-adjectives-related-to-nouns_from_mining-for-meaning-2.png
red (often), yellow (sometimes), tasty (very often), fast (hardly ever) ... apple
red (hardly ever), yellow (very often), tasty (often), fast (hardly ever)... banana
red (sometimes), yellow (sometimes), tasty (hardly ever), fast (often) ... car
red (very often), yellow (sometimes), tasty (hadly ever), fast (sometimes) ... truck
Algorithm used = "co-sine similarity measure"
then... (the text continues)
We applied this approach to automatically annotate new adjectives, based on their semantic relatedness to gold1000 [= hand annotated] adjectives. From the TWNC [Twente Nieuws Corpus (TwNC)] (Ordelman et al., 2002), we analyzed 3,000,000 words and selected the top 2,500 most frequent nouns. For each adjective in TWNC that is also in the CORNETTO [dutch language, dutch counterpart WordNet] database, we counted the number of times it directly precedes one or more of these top nouns, resulting in 5,784 adjective vectors with 2,500 vector features. For each gold1000 [= hand-annotated] adjective we then used cosine similarity [= algorithm described by Tim van de Cruys] to retrieve the top 20 most similar nearest neighbors [what is neighbouring what?]. For fantastisch (fantastic) the top five nearest neighbors are: geweldig (great, 70%), prachtig (beautiful, 51%), uitstekend (excellent, 50%), prima (fine, 50%), mooi (nice, 49%) and goed (good, 47%).
beautiful - book: x times
beautiful - person: z times
beautiful - apple: y times
---
adjective vector
features: book, person, apple (ny)
translated into a mathematical matrix, it will look like:
horrible - book: y times
example try:
- For each gold1000 --> fantastic
- appears in the gold1000 with 10 different nouns --> a1[n1, n2, n3, n4, n5, n6, n7, n8, n9, n10] --> is the adjective vector
- great, beautiful, excellent, fine, nice, good
- --> are already hand-annotated / or not
- --> have adjective vectors as well
- --> are these two adjective vectors then compared?
en-sentiment.xml
pattern's sentiment analysis uses a list of English adjectives in a xml file (in the pattern-2.6.zip file, it's located in pattern-2.6/pattern/text/en/). this file is also used by other projects (mentionning pattern) found after a very quick research :
TextBlob (Simple, Pythonic, text processing--Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more) https://github.com/sloria/TextBlob (this software uses two other sentiment analyzers)
Emotional (Subjectivtiy and sentiment/polarity analysis library for Node.js) https://github.com/ticup/emotional
fr-sentiment.xml
pattern's sentiment analysis for French uses a list of French adjectives in a xml file (in the pattern-2.6.zip file, it's located in pattern-2.6/pattern/text/fr/). this file is also used by other projects (mentionning pattern) found after a very quick research :
TextBlob (Simple, Pythonic, text processing--Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more) https://github.com/sloria/TextBlob (it seems that it is not the same version than for pattern, version 1.0 instead of 1.1 fpr pattern 2.6)
how about going forwards?
text-mining methods, text-mining culture
- document the steps that has been put on the table during this edition of Relearn, and has been produced since Cqrrelations
- how would you make it (a text-mining-process) better?
- - what is better?
- - less suggestive?
- - more efficient?
- - ...
- - does it become better by
- - giving critique on it?
- - play with it? being goofy?
- what would an algorithm do?
- let's make a critical fork of Pattern (how are we going to call it ? Pattern the critical edition, PatternPlus
- - as a form of annotation of Pattern
- - there is already annotation present from the Pattern team, but this is focused on an urge to show how the data speaks
- - additional files that go into the package, reacting on the files of Pattern
- - which might include a check-me.txt file
- - in some packages there is an ADD-TO-DO or ADD-FIX-ME file
Google Group question: sentiment_score()
answered by Tom de Smedt
http://10.9.8.7/training-common-sense/sources/pictures/if-happy-is-0.0-something-is-wrong.png
https://groups.google.com/forum/#!topic/pattern-for-python/FTeqb0p5eFM (this question)
Pattern on the web
Pattern's Github --> https://github.com/clips/pattern
Pattern's Google Group --> https://groups.google.com/forum/#!forum/pattern-for-python
backing-up: Cqrrelations
Cqrrelations is a work session lasting from 12 till 23 January 2015, in which a wide range of forms of life coming from different backgrounds in arts, literature, science and computing will gather to reflect on the influence of models and digital traces over our daily reality and language. The work session is a space for theories and practices, for experiments, discussions, prototypes… Human and non-human (in-)expertise will facilitate the exploration the topic. Parts of the process will be documented on this platform, possibly to end up in some forms of publication later on.
Organised by Constant with the support of deBurenPublic events are organised in collaboration with deBuren, CPDP and Recyclart
www.cqrrelations.constantvzw.org/
pictures of the week: http://gallery3.constantvzw.org/index.php/Cqrrelations